1.10 요약
- 머신러닝과 신경망에 대한 기본적인 내용
- 뉴런의 기본 구조
- 전방향 신경망의 작동방식
- 비선형이 복잡한 학습 문제를 해결하는데 중요한 이유
1.1 지능형 기계 만들기
인간의 뇌? 이미지를 인식 / 물체를 식별 / 음성 구분 / 물리 법칙 직관 / 물체 추적 / 연관 짓기 / 복잡한 문법 이해 / 어휘력 등
복잡한 문제를 어떠한 방식으로도 풀어내는 능력을 가졌다.
인간의 뇌와 유사한 기능하게 기능하는 기계를 만들기 위해서는 지금까지 와 다른 컴퓨터 프로그래밍 방식을 개발해야 함
그 방식이 바로 "Deep Learning"이다
1.2 기존 컴퓨터 프로그램의 한계
컴퓨터는 다음에 아주 능하다
- 매우 빠르게 연산
- 명시적으로 명령어 리스트를 수행
기존까지의 프로그래밍 방식은 어떤 것이었는가?
"Limitaion of explicit programming" 방식으로, 프로그래머가 하나하나 상황/조건에 해당하는 logic을 지정하는 방식이었다.
하지만 하나하나 모든 상황/조건을 지정해주기엔 매우 복잡하고, 애매한 상황들이 많이 있다
ex ) 손으로 쓴 숫자 "0"을 구별하기
조건 1) 하나의 폐곡선으로 이루어져 있다

문제점 : 0을 쓸 때 동그라미를 닫지 않으면 인식이 불가능함
조건 2) 고리의 시작점과 끝점 사이의 한계 거리를 설정
문제점 : 6과의 구분이 어려워짐
이와 마찬가지로 사물 인식, 음성 구분, 자동 번역 등도 마찬가지이다.
인간의 뇌라면, 이를 보고 0 임을 판단할 수 있지만 하나하나 logic을 지정해야 하는 컴퓨터로는 구현하기는 너무 많고 복잡하다.
그렇다면 컴퓨터도 인간과 같이 어떤 자료를 통해 스스로 학습하게 하면 어떨까? => Machine Learning( 아서 사무엘 / 1959)
1.3 머신러닝의 작동원리
특정 문제/사물을 경험을 통해 인식하고, 그 인식이 틀렸을 때는 그것을 수정함으로써 인지하는 방식(실제 사례를 통한 경험)
Machine Learning의 종류
1. Supervised
-label이 되어있는 data(trainin set)을 이용하여 학습시킴 ( 고양이 사진을 주고 고양이, 강아지 사진을 주고 강아지 임을 알려줌 )
- 스팸메일 검사 / 이미지 맞추기 / 성적 예상 등
2. Unsupervvised
-label이 되어있지 않은 data를 이용하여 학습시킴
-word clustering 등
컴퓨터에게 규칙(logic)을 가르치지 않고,
경험들을 평가할 수 있는 "모델", 실수 시 모델을 수정하기 위한 "명령어 집합"을 제공
시간이 지나면 모델이 문제를 정확하게 풀 수 있을 거라고 기대함
예를 통해 설명하면,
수면시간, 공부시간(x)을 통해 시험 점수가 평균 이상인지 이하인지 예측(y)하는 모델(h(x,θ))을 만드려고 한다
입력 데이터 x가 주어지면, 학습시킨 모델인 h(x,θ)를 통해 결과를 예측(y)
결과 y를 최대한 정확하게 예측하기 위해서는 *파라미터 벡터 θ의 최적 값을 구해야 함
*파라미터 벡터 θ 는 벡터 값으로 표현되며, 정확한 예측을 가능한 많이 할 수 있도록 분류기를 배치하는 하도록 하는 값을 구해(최적화) 야하는데
그것을 최적 파라미터 벡터라고 함
얻으려는 값/예측 결과 (y)
- -1 (점수가 평균 미만인 경우)
- 1 (점수가 평균 이상인 경우)
입력 데이터 (x = [x1 x2]^T)
*입력 데이터가 2개로 주어지는 경우
x1 : 수면시간
x2 : 공부시간
h(x,θ)
*x와 θ는 벡터이므로 내적(⋅)을 이용

에서 정확한 예측을 가능한 한 많이 할 수 있게 하는 "최적 파라미터 벡터"를 찾아야 함

모델을 학습시키기 위해 제공한 실제 사례의 데이터셋 14개를 제공한다
x = (수면시간, 공부시간) y= 성적의 평균 미만/이상 여부
x = (0.5, 5) , y= -1
x = (1, 4) , y= -1
x = (1, 7) , y= 1
x = (2, 1) , y= -1
x = (2, 6) , y= 1
x = (3, 2) , y= -1
x = (3, 4.5) , y= 1
x = (4, 0.5) , y= -1
x = (5, 1) , y= -1
x = (5, 4) , y= 1
x = (5, 6) , y= 1
x = (6, 3) , y= 1
x = (7, 7) , y= 1
x = (8, 1) , y= 1
이를 그래프에 표현하면, (1은 + , -1 은 -로 표현)

이와 같이 표현할 수 있다.
다음의 그래프에 있는 점선(선형 분류기)을 기준으로 삼으면,
주어진 데이터 셋 14개에 대해 정확한 예측을 할 수 있다
다음의 점선은 3*x1 + 4*x2 - 24 = 0 이므로
* 다음과 같은 모델을 선형 퍼셉트론이라고 한다
최적 파라미터 벡터 θ = [-24 3 4]^T이고,
이러한 최적 벡터를 가진 모델 h(x,θ)는

로 나타낼 수 있는 것이다.
학습을 바탕으로 제작된 모델을 이용해보자.
그렇다면, 수면시간 2시간 공부시간 3시간의 데이터가 주어진다고 해보자
x1= 2 , x2 = 3이고,
3*2 + 4*3 - 24 = -6 < 0 이므로 평균 이하의 점수(y = -1)가 나올 것이라는 예측을 할 수 있다
그래프에서 알 수 있듯 실제 사례의 데이터셋이 많으면 많을수록 최적 파라미터 벡터의 선택 폭을 좁혀 더 좋은 최적 벡터를 구할 수 있게 된다.
위의 예시를 보면 두 가지 의문점이 남는다.
- 파라미터 벡터 θ의 최적 값을 어떻게 구하는가? (2장에서 자세히)
- 위의 선형 퍼셉트론 모델로 모든 관계에 대한 학습이 가능한가? -> 불가능 , 사물 인식 문장 분석과 같은 복잡한 문제와 데이터는 비선형이 대부분이다.
이를 해결하기 위해 뇌가 사용하는 구조와 유사한 모델을 만들기 위한 노력이 계속되었고 이것이 Deep Learning 연구의 본질
그렇다면 인간의 뇌가 사용하는 구조를 알아보자
1.4 뉴런
뇌의 기본단위는 뉴런으로 뇌에 1만 개 이상의 뉴런이 존재, 각 뉴런은 다른 뉴런과 평균 6000개의 연결을 형성한다.
뉴런의 정보 처리 방식은 다음 그림과 같다
뉴런은 자극이 세지면 반응의 빈도가 높아진다.
여러 뉴런들을 통해 정보가 들어오므로 빈도수가 높은 정보는 output을 생성할 때 기여도(가중치)를 높게 가진다

이와 유사하게 뉴런의 기능을 인공적 모델로 변경하면,
1. 인공 뉴런은 n개의 입력(x)을 받고, 각각 입력에 대한 특정 가중치 값(w)을 가진다. => Inputs
2. 각각의 입력과 그에 해당하는 가중치를 곱하여 모두 더한다 ( 해당 값을 z , 신경 세포의 로짓 logit이라고 함) => Strengths and Sum
* 이때 로짓 z는 대부분의 경우에 상수(bias)를 포함한다. 즉, z = (Xi*Wi를 모두 더한 값) + b //1.3의 예시에서 -24와 같은 것
3. z를 함수 f를 통해 계산한다 f(z) = y. => Transform
4. y를 다른 뉴런으로 전송 => Output

1.5 뉴런으로 선형 퍼셉트론 표현하기
1.3에서 선형 퍼셉트론의 예시를 보았다. 이것을 뉴런으로 표현해보자
좌표 평면을 두 개로 나누는 하나이 선을 사용 ( 선형 퍼셉트론 분류기 -> 점선 )했었다.
또한, 이 선형 퍼셉트론 모델(h)은 다음과 같다, 또한 하나의 뉴런을 사용하고 있음을 알 수 있다.
이 식을 보면,
x1에 대한 가중치(w1)는 3 , x2에 대한 가중치(w2)는 4, bias(b)는 -24 인 // 2개의 입력값과 1개의 bias를 가지고 있음
z = x∙w + b 임을 알 수 있고,
이를 이용해 위의 식을 다시 보면, 사용된 함수 f는 다음과 같음을 알 수 있다.

또한, b = -24 가중치 w1=3, w2=4이고, 최적 파라미터 벡터θ = [ -24 3 4 ] 였던 것을 보면,
가중치의 값은 최적 파라미터 벡터를 구성하는 것을 알 수 있다.
다음을 1개의 뉴런(단일 뉴런)으로 그려보면

다음과 같다
즉, 선형 퍼셉트론 모델(h)과 위의 그림의 뉴런 모델이 완벽하게 동일하다는 것을 알 수 있다.
일반적으로 단일 뉴런이 선형 퍼셉트론 보다 훨씬 표현력이 뛰어나다.

그럼에도 불구하고, 단일 뉴런으로는 복잡한 문제를 해결할 수 없다 ( 뇌는 여러 개의 뉴런으로 이루어짐 )
1.6 전방향 신경망
사람 뇌의 뉴런은 층으로 구성된다.
눈, 코, 입 등으로 받아들이는 감각 입력(input)이 6개의 층을 거쳐 처리된 후, "고양이를 보고 있다"는 개념적 이해(output)의 결론을 내린다.
이러한 층 개념을 이용해 인공신경망(artificial neural network)을 만들 수 있다.
여러 가지 신경망이 있지만 여기서는 전방향 신경망에 대해서 잠깐 다루고 더 복잡한 건 뒷부분에서
전방향 신경망은 "데이터가 아래층에서 위층으로만 이동" 한다는 특징을 가졌다(2장에서 자세히)
| Output Layer(출력층) | Hidden Layer(은닉층) | Input Layer(입력층) |
| 출력값을 계산함 | 출력층과 입력층 사이에 존재하는 Middle Layer |
입력 데이터를 가져옴 |
| 출력값은 벡터로 표현 | - 문제 해결을 위한 유용한 특징들을 스스로 학습하여 발견함 - 입력층보다 뉴런의 수가 적음 ( 압축된 표현들을 배우도록하기 위해서 ) |
입력값은 벡터로 표현 |
| - 모든 출력이 다음 층에 있는 모든 뉴런과 연결 될 필요는 없음 ->경험으로 부터 얻어짐 | ||
으로 구성되어있으며, 그림으로 나타내면 이러하다

이와 유사하게
신경망을 수학적으로 연속된 벡터와 행렬 연산으로 표현할 수 있다.
연속된 벡터
Input(크기 :n) : X = [x1 x2... xn]
Bias(크기 :m) : B = [b1 b2... bm]
행렬
Weight(크기 : n x m 행렬)
과 함수 f(z)을 이용하여, 다음을 구한다.
Output(크기 : m) : Y = [y1 y2... ym]

1.7 선형 뉴런과 그 한계
뉴런의 유형은 로짓 z에 적용되는 함수 f에 의해 결정된다
f(z) = az + b와 같은 일차식 (선형 함수)라면, 선형 뉴런을 사용한다. (계산이 쉬움)
예시)
f(z) = z 인, 패스트푸드점에서 식사비용을 추정하는 선형 뉴런
각 가격에 대한 가중치를 적용

선형 뉴런은 Hidden Layer가 없는 신경망으로 표현될 수 있다.
Hidden Layer는 문제 해결을 위한 유용한 특징을 학습하는 계층이므로, 이 계층이 없으면 복잡한 관계들을 학습하기 어렵다.(한계)
복잡한 관계를 학습하기 위해서는 비선형 함수 f를 사용하는 뉴런들을 이용해야 한다
비선형 함수의 예를 알아보자(1.8)
1.8 시그모이드, tanh, RELU뉴런
비선형 함수를 적용한 뉴런은 대표적으로 3가지(시그모이드/쌍곡 탄젠트/ReLU)가 있다.
이 활성화 함수 3가지는 각 층의 뉴런에서 다음 계층으로 전달할 값을 계산 때 사용한다. (출력층에서의 최종 값은 다른 함수 사용->1.9)
참고)
input 데이터를 Output데이터로 바꾸어주는 함수를 활성화 함수(f)라고 한다
Input X = [x1 x2... xn]
f(z) = Y
Output Y = [y1 y2... ym]
그전에 잠깐 계단 함수에 대해 설명하고 가도록 한다.
계단 함수(step function)
퍼셉트론은 활성화 함수로 계단 함수를 사용한다.
1.3에서 예제로 나왔던 선형 퍼셉트론을 다시 한번 살펴보면,
값이 연속되지 않고 -1, 1으로 급격하게 변화하는 것을 알 수 있다.

계단 함수는 이와 같이 값이 연속되지 않고 갑작스럽게 변화한다.
(사실 아직 잘 모르겠는 건 계단 모양? 급격히 변하는데 의의가 있는 것인지 , 꼭 값이 1 , 0 이어야 하는지..)
+ 추가) 퍼셉트론이 계단 함수를 이용하는 이유는 뉴런을 모방했기 때문이 아닐까
실제 뉴런은 역치 이상의 자극을 받지 않으면 아예 반응하지 않고, 역치 이상의 자극을 받아야만 반응한다
(자극의 세기에 따라 반응의 크기가 달라지는 것이 아닌 빈도가 달라지는 것)
이를 모방하여 역치(특정값) 이상이면 반응(1) , 이하면 반응하지 않음(0) 이므로 계단 함수를 사용하는 것이 아닐까 생각
실제 계단 함수는 특정 값 이상이면 1 이하면 0을 반환한다.

haje01.github.io/2019/11/19/logit.html 참고
1. 시그모이드(Sigmoid : S자 모양의) 뉴런
시그모이드 뉴런이 사용하는 시그모이드 함수는 다음과 같다

이 함수를 그래프로 표현하면,

그래프를 보면 s자 모양의 곡선이지만, 큰 틀로 보면 계단 함수와 유사한 형태임을 알 수 있다.
계단함수와 달리 완만하고 매끄럽게 변화하는데, 이 변화가 신경망 학습에서 중요한 역할을 한다(아마 후에 자세히 나올 것)
logit(z)가 아주 클 때는 1로,

logit (z)가 아주 작을 때는 0으로,

범위는 1~0 임을 알 수 있다.
위의 식이 이해가 가지 않는다면,

이렇게 바꾸어 생각하면 더 쉽다.
z가 ∞로가면, 1/e^∞ = 0 이므로, 1/1+0 = 1
z가 -∞로 가면, e^(-z) = e^(- -∞) = e^(∞) 이므로, 1/1+∞ = 0
2. tanh(쌍곡 탄젠트) 뉴런
tanh 뉴런이 사용하는 tanh 함수는 다음과 같다

이 함수를 그래프로 표현하면 다음과 같다
tanh(z) 그래프는 중심이 0이므로 시그모이드 뉴런보다 선호되는 경우가 많다


변형하는 법)

logit(z)가 아주 클 때는 1로,

logit (z)가 아주 작을 때는 -1으로,

범위는 -1~1 임을 알 수 있다.
3. ReLU 뉴런
ReLU(restricted linear unit, 렐루/ 제한된 선형 유닛) 뉴런이 사용된다
사용되는 활성화 함수는 다음과 같다.

즉, 입력값이 0을 넘으면 입력값을 그대로 출력하고, 0 이하이면 0을 출력하는 것
그래프로 표현하면 다음과 같다

몇 가지 단점에도 불구하고, 많은 이유로 ReLU는 최근까지 다양한 작업에서 사용된다. (5장에서 자세히)
1.9 소프트맥스 출력층
마지막 계층인 출력층(Output Layer)에서는 "소프트맥스 함수"라는 활성화 함수를 사용한다.
위에서 잠깐 언급했던 Supervised Learning에는 크게 2가지 종류가 있는데
Regression(회귀) : 값이 연속적인 수치(범위 내의 수?)로 계산됨
ex) 점수 예측
Classification(분류) : 결과가 어디에 속하는지를 알려줌
- Binary classification (2가지 중 어디에 속하는지) 예 : Yes/No , P/NP
- multi-label classification (여러 가지 중 어디에 속하는지) 예: 등급(A, B, C, D, F) 예측
소프트 맥스(softmax) 함수는 Regression 문제에 사용되는 함수이고,
항등(Identity) 함수는 Classification 문제에 사용되는 함수이다.
소프트맥스 출력층은 다른 층과 달리 그 층의 모든 다른 뉴런의 출력에 의존한다
-> 다른 층(Hidden Layer)을 보면
해당 계층에서 n개의 노드 중"특정 i번째 노드"로 들어온 입력이 해당 노드의 f함수를 거쳐 y로 출력되어 다음 계층에 전해진다.
그러나 소프트 맥스 출력층은 그 층의 0~m번째 노드까지 모든 노드의 출력에 의존한다
그 이유는 모든 출력의 합이 1이 되어야 하기 때문이다. (밑에서 설명)
소프트 맥스 함수는 다음과 같다

n : 출력층의 뉴런의 개수(출력 노드의 수)
분모인 Zi : i번째 출력층 뉴런의 로짓
분자는 출력층의 모든 e^(z 0 ~ z n)의 합을 의미한다
yi는 출력층의 i번째 노드(뉴런)의 출력을 의미한다
위에서 설명했듯

출력층의 모든 뉴런의 출력의 합은 1이고,
모든 뉴런의 출력은 0과 1 사이이다.
이는 "확률"의 개념이 사용되었기 때문이다. 왜냐하면??
보통 최종 출력되는 벡터는 (상호 배타적인 레이블의 집합인) *확률 분포가 되길 바라는 경우가 많다.
상호 배타적 : 두 사건이 동시에 일어날 확률이 0인 경우
A, B 두 사건이 있을 때,
P(A or B) = P(A) + P(B)
P(A and B) = 0 인경우를 뜻함
확률분포
확률 변수가 특정한 값을 가질 확률을 나타내는 함수이다

확률을 다 더하면 1이다.
예측값으로 나올 수 있는 모든 후보중에서 특정 후보가 100%확률로 맞기란 쉽지 않다.
그렇기 때문에, 소프트맥스 함수를 이용하여 확률분포처럼 표현하여, 어떤 후보가 가장 높은 확률일지 알아내는 것이다
예를 들어,
MNIST데이터셋에서 손으로 쓴 숫자를 인식하는 신경망을 만든다면,

0~9까지는 상호 배타적이지만, 100%신뢰도로 숫자를 예측할 수는 없다.
확률 분포를 사용하여 우리가 한 예측의 신뢰도가 어느정도인지 표현하는 것이다.
결과적으로 우리가 원하는 출력 벡터 Y = [y1 y2 ... y10] (출력층 노드가 10개(0~9까지이므로))는 다음과 같은 형태(확률)로 표현할 수 있다.
[p0 p1 ... p9] : 각각 입력값이 0일 확률, 1일 확률, ... 9일 확률 // 합은 1이다
출력층의 함수(소프트맥스 함수)의 출력을 "확률"로 해석이 가능하다는 의미이다.
강한 예측(Strong prediction)과 약한 예측(Weak prediction)
강한 예측
출력 벡터중 하나의 항이 1에 가깝고, 나머지는 0에 가까운 것
위의 MNIST의 예시)
Y = [0.02 0.01 0.8 0.01 0.08 0.01 0.03 0.02 0.02 0.01] // 입력값이 2일 확률이 가장 높음

약한 예측
가능성이 거의 같은 여러개의 가능한 레이블을 가지는 것
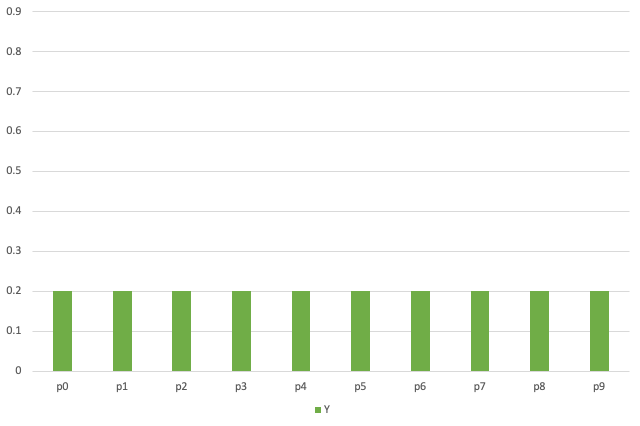
Y = [0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2] ?? 0.1이어야 하네요...오타..~
참고자료
딥러닝의 정석(Fundamentals of Deep Learning) - 니킬 부두마
모두를 위한 머신러닝 (Youtube)
문과생도 이해하는 딥러닝 (2) - 신경망 Neural Network
2017/09/27 - [Data Science/Deep Learning] - 문과생도 이해하는 딥러닝 (1) - 퍼셉트론 Perceptron 한동안 인스타나 기타 SNS 크로러를 개발하느라고 딥러닝 정리가 조금 소홀했었다. 딥러닝과 집적 관련된 내용
sacko.tistory.com
[딥러닝] 소프트맥스 함수(Softmax) : 출력층 활성화 함수
신경망을 구현할 때, 여러 층을 겹쳐서 설계하게 된다. 각 층의 뉴런에서 신호를 전달 할 때, 가중치와 입...
blog.naver.com
'ML' 카테고리의 다른 글
| [딥러닝의 정석] 05. 합성곱 신경망-1 (0) | 2020.08.02 |
|---|---|
| [딥러닝의 정석] 04. 경사 하강법을 넘어서 (0) | 2020.07.27 |
| [딥러닝의 정석]03. 텐서플로로 신경망 구현하기-2 (0) | 2020.07.21 |
| [딥러닝의 정석]03. 텐서플로로 신경망 구현하기 (0) | 2020.07.18 |
| [딥러닝의 정석]02. 전방향 신경망 학습 (0) | 2020.07.12 |



