3.14 요약
텐서 플로우 사용법 : 세션과 변수 / 연산 / 그래프 계산 / 장치 관리 및 주요 기능
텐서 플로우 : 머신러닝 모델을 표현하고 학습시키는 라이브러리
전방향 신경망 구현 : 로지스틱 회귀 모델 / 확률적 경사 하강법
3.1 텐서 플로(Tensor flow)란?

텐서 플로 :
- 개발자가 딥러닝 모델을 설계하고 만들고 학습시키는 것을 더 쉽게 하도록 구글이 공개한 오픈소스 소프트웨어 라이브러리
- data flow graphs를 이용하여 numerical computation이 가능함
- Python을 이용
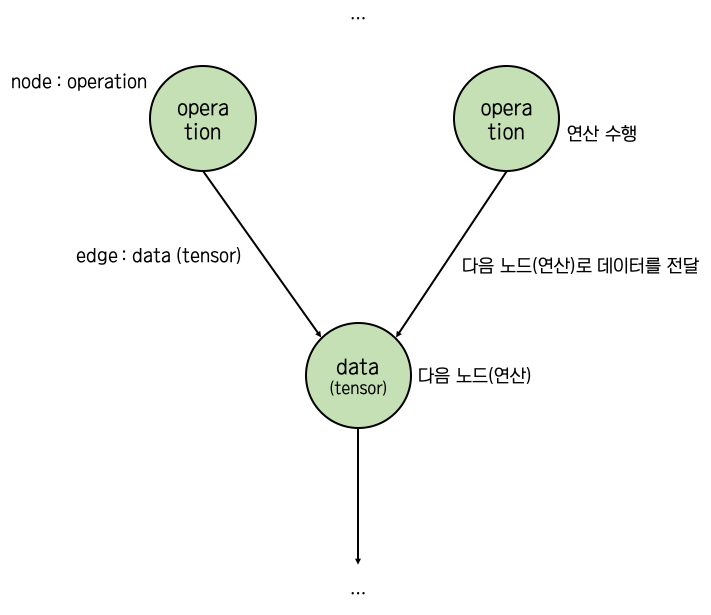
data flow graph란?
*그래프 : 노드와 에지로 구성
노드(연산)와 에지(데이터)를 이용하여 , 노드와 에지의 흐름을 거치면서(flow) 어떠한 사용자가 원하는 연산이 일어나서 원하는 결과물을 얻는 것이 data flow graph이며, 이를 구현해 주는 것이 "tensor flow"이다
데이터(tensor)의 흐름(flow)이 결국엔 어떤 결괏값(result)으로 나오니 tensor flow라는 이름이 매우 직관적으로 지어진 이름이라는 것을 확인해 볼 수 있습니다.
텐서 플로에서 데이터는 텐서(tensor)라고 하는데, 이 텐서는 다차원 배열이라고 많이 정의한다.
또한, 백터와 행렬을 일반화한 것(고차원으로 확장 가능)이라고 보통 많이들 표현한다.
텐서에 대해 자세히 알아보려고 했으나, 텐서에는 수학적 개념, 물리적 개념으로 설명이 나누어져 있고 찾다 보니 수학과나 물리학과 학생들도 정확히 이해하기 어려운 개념이라고 하니 , 사실 인공지능을 공부하는 우리는 그렇게 깊은 본질적 고찰까지 어렵게 하는 것이 더 손해인 것 같습니다.
마침 Deep Learning에서의 텐서를 적절하게 설명해주신 영상이 있어서 그 기반을 토대로 설명하려고 합니다.
| rank | type(name) | 설명 | example |
| tensor of Rank 0 | scalar | 숫자를 값으로 가짐 |  |
| tensor of Rank 1 | vector | Rank 0의 Tensor(scalar)를 구성요소로 가짐 |  V = [ 1 2 ] |
| tensor of Rank 2 | matrix | Rank 1의 Tensor(vector)를 구성요소로 가짐 |  |
| tensor of Rank 3 | 3 tensor | Rank 2의 Tensor(matrix)를 구성요소로 가짐 | 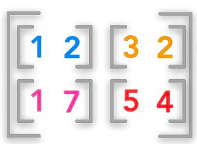 |
| tensor of Rank N | N tensor | Rank N-1의 Tensor를 구성요소로 가짐 |
흔히 Tensor라고 하면, 3 Tensor를 의미합니다
더욱 자세한 이해를 돕기 위해 자연어 처리로 Tensor의 예시를 들어봅시다
Hi John
Hi James
Hi Brian
3개의 문장이 있습니다.
이 문장을 자연어 처리하기 위해 하나의 독립적인 unique 한 word를 구분 짓기 위하여 인덱싱을 해봅시다
| Unique word | Index |
| Hi | 0 |
| John | 1 |
| James | 2 |
| Brian | 3 |
각각 Unique word를 scalar값으로 표현했다고 볼 수 있습니다.
이제 자연어 처리에서 사용하는 인코딩 방식(벡터로 만들기)을 적용해보면,
*One Hot Encoding : 자연어 처리에서 사용하는 인코딩 방식으로, 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1을, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식
이렇게 표현하게 되면, word들을 같은 크기의 vector로 표현하는 동시에 각각 다르게 구분할 수 있게 됩니다.
| Unique word | index | One Hot Encoding |
| Hi | 0 | [1,0,0,0] |
| John | 1 | [0,1,0,0] |
| James | 2 | [0,0,1,0] |
| Brian | 3 | [0,0,0,1] |
각각 Unique word를 vector값으로 표현했다고 볼 수 있습니다.
word를 vector로 표현했으니, 이 word가 사용된 문장 또한 vector로 나타내어 볼 수 있을 것입니다.
| Sentence | 벡터 표현 |
| Hi John | [ [1,0,0,0], [0,1,0,0] ] |
| Hi James | [ [1,0,0,0], [0,0,1,0] ] |
| Hi Brian | [ [1,0,0,0], [0,0,0,1] ] |
각각 문장의 구성요소로 word (vector)를 가졌으니, 문장을 벡터로 표현한 것은 곧 matrix로 표현된 것이 됩니다.
이를 문장 데이터들을 인공신경망에 학습시킨다고 가정해봅시다.
우리는 2단원에서 mini-batch-gradient descent에 대해 알아보았고, 이 것이 주로 사용되는 방법임을 알았습니다.
미니 배치 경사 하강법은 반복마다 전체 데이터셋의 부분집합을 학습시키는 것인데,
우리는 3개의 문장만을 가지고 있지만 실제로는 전체 데이터 셋은 더 크다고 하고,
즉 한 문장씩 학습시키는 것이 아니라 이 3개를 하나의 부분집합이라고 가정하면,
이 3개를 부분집합으로 하여 인공신경망에 제공할 것입니다.
문장을 matrix로 표현했고 이를 다시 부분집합으로 표현한다면,
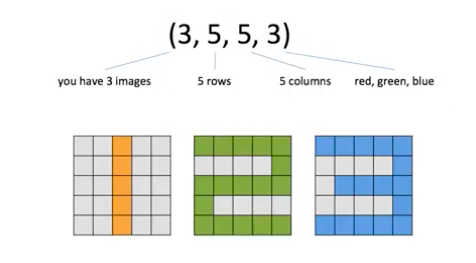
matrix를 구성요소 가지는 3 Tensor로 표현됩니다
[ Hi John, Hi James, Hi Brain ]
[ [ [1,0,0,0], [0,1,0,0] ] , [ [1,0,0,0], [0,0,1,0] ], [ [1,0,0,0], [0,0,0,1] ] ]
Shape = ( 3 , 2 , 4 ) 3d Tensor
3 : 부분집합에 들어가는 문장(sentence)의 수
2 : 각 문장에 포함된 단어(word)의 최대 개수
4 : 단어가 몇 개의 숫자(index의 수, scalar)로 표현됐는가


수학적으로나 물리적으로 들어가면 텐서는 매우 복잡하고 어려운 개념인데, 우리는 여기까지만 알아도 충분할 것 같습니다
더 알아보시고 싶은 분은 이 영상을 참고하시면 될 것 같습니다(저는 봤는데 3D tensor부터 무슨 소린지...)
3.2 텐서 플로와 대안들을 어떻게 비교할까?
텐서 플로우 말고도 다른 라이브러리가 많은데 왜 텐서 플로인가?

- 여러 방법으로 점수를 매겨본 결과 텐서 플로우가 가장 압도적
- 많은 사람들이 사용하다 보니 자료의 양도 많음
- 초보자들도 대부분 널리 알고 있는 파이썬 언어를 사용하기 때문에
그럼 다른 라이브러리에는 어떤 것들이 있는지 한번 알아봅시다. ( 책에 있으니 조금 알아봤습니다만, 넘기셔도 될 듯 )
티아노(Theano)/토치(Torch)/카페(Caffe)/니온(Neon)/케라스(Keras) 등등
2017년 기준 속도는 티아노와 토치가 조금 더 빨랐다고 하는데 지금은.. 어떤지 모르겠습니다
텐서 플로(Tensor Flow)
구글팀에서 개발 2015년 오픈소스로 공개
파이썬 언어 사용
모바일 환경에서 동작 가능
한 컴퓨터에서 여러 GPU로 확장되는 모델을 쉽게 구축
분산 방식으로 대규모 망을 학습시킬 수 있음
티아노(Theano)

수학적 표현을 정의하고 보기 좋게 만들고 평가하는 파이썬 라이브러리
몬트리올 대학교 LISA Lab에서 만듦
활발한 개발자 커뮤니티 존재 (2017년 기준)
다른 확장 학습 프레임워크와 달리 확장성이 뛰어나지 않으며 다중 GPU 지원이 부족
라이브러리가 텐서 플로우에 비해 명확하지 않음
현재 개발이 중단됐다고 하네요.. 이 책 티아노로 하려다가 말았다는데 큰일 날 뻔
토치(Torch)

Lua라는 스크립트 언어를 사용함
페이스북/트위터/구글 등과 같은 곳에서 사용하고 개발함
최대한의 유연성, 모델 제작과정이 간단한 것이 목표
파이 토치(PyTorch)라는 게 개발되었다고 하네요
케라스(Keras)

파이썬 기반으로 작성되었음
매우 가볍고 배우기 쉬움
직접 모델을 만들기에 매우 좋지 않아 Theano/Tensor Flow에서 작동하도록 구성이 가능함
3.3 텐서 플로 설치하기
저는 mac Air 2017형을 사용 중이며, (안타깝게도 GPU가 Intel이라 gpu지원이 어렵다고 함)
Anaconda와 Jupyter Notebook을 이용하여 텐서 플로우를 사용할 것이고,
Tensor Flow version 1 / Python version 3.7 / numpy Version 1.17 사용할 것이고요
Terminal을 이용해 설치할 겁니다
아나콘다 / 파이썬 / 넘 파이에 대해선 넘어가고 텐서 플로우에 대해서만 설명합니다.
저도 이것저것 설치하고 시행착오를 많이 겪었는데... 일단 이게 맞는지는 모르겠으나 되긴 하니까 방법 공유하는 느낌으로...
1. 파이썬 3.7 설치
www.python.org/downloads/release/python-373/
Python Release Python 3.7.3
The official home of the Python Programming Language
www.python.org
2. 아나콘다 설치
The World's Most Popular Data Science Platform
Anaconda is the birthplace of Python data science. We are a movement of data scientists, data-driven enterprises, and open source communities.
www.anaconda.com
3. 텐서 플로우 및 주피터 노트북
(1) 가상 환경 만들기
conda create -n tensorflow python=3.7 //가상환경 이름을 tensorflow로 지정

(2) 가상 환경 활성화
conda activate tensorflow //가상환경이름

(3) 텐서 플로우 1.14 ver 설치
pip install tensorflow==1.14그냥 텐서 플로우를 설치하면 버전 2.2.0이 설치되는데 , 현재 많은 강의들이 1 버전으로 설명하는 것도 있고(이 책도 그렇고)
2 버전에서는 더 이상 Session을 사용하지 않는데, 이 책의 3.7에서 session을 설명하니 그냥 1.14 버전으로 설치했다

되는지 확인하고 싶으면,
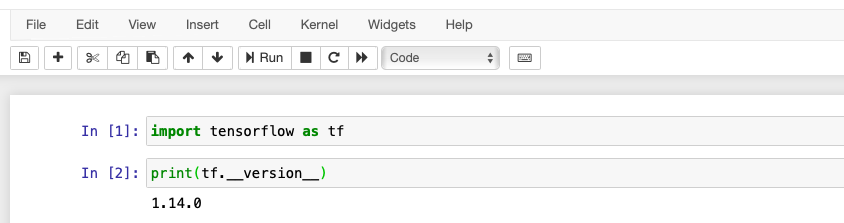
python //파이썬이 실행됨
import tensorflow as tf
print(tf.__version__) //설치한 텐서플로우의 버전이 출력됨
(4) 주피터 노트북 연동
conda가상 환경에서 jupyter notebook을 열었을 때, 설치한 패키지들이 import 되지 않는 현상이 발생할 수 있다.
jupyter 패키지를 설치하면 해결이 가능하다
conda install jupyter
(5) 주피터 노트북 실행
jupyter notebook
*발생했던 오류

numpy버전이 1.17 이상인 경우 이런 오류가 발생한다
pip install "numpy<1.17"으로 버전을 내려주면 문제가 해결된다
(6) 주피터 노트북 연결 해제
사용하던 파일의 Close and Halt를 눌러서 Running을 종료

왼쪽 상단의 Quit을 눌러주면 연결이 해제된다



(7) 가상 환경 비활성화
conda deactivate
(8) 터미널 종료
exit

Jupyter notebook을 이용하여 책에 나온 예제를 따라 해 봤습니다.

Deep Learning앞에 출력되는 b는 Byte Literal(Byte String)을 의미합니다.
다른 예제를 통해 data flow graph를 좀 더 자세히 설명해봤습니다
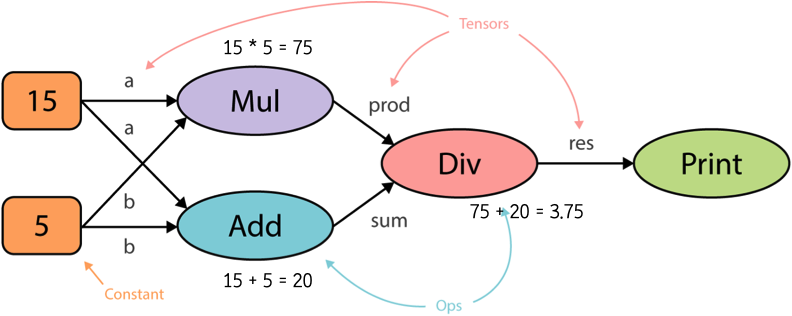
여기 data flow graph가 있습니다
node는 연산을 , edge는 data(tensor)를 의미한다고 했었습니다.
이를 텐서 플로우 코드로 구현하면,

constant도 함수이니 하나의 연산으로 볼 수 있을 것 같습니다. (아래에서 자세히)
각각의 노드에 연산을 수행하고 데이터에 연산 값을 수행해준 뒤
값 확인을 위해 run으로 제대로 된 값이 나오는지 확인해 보았습니다.
어떤 느낌인지 감이 오셨길 바랍니다.
3.4 텐서 플로 변수 만들기와 조작하기
3.5 텐서 플로 연산
3.6 placeholder 텐서
이 세 가지를 왜 이 순서로 배치했는지, 대체 왜 이렇게 나누었는지.. 공감이 안 가므로 통합해서 제 마음대로 설명하도록 하겠습니다.
텐서 플로우의 메커니즘
먼저 본격적으로 시작하기 전에 텐서 플로우의 메커니즘에 대해 알아봅시다
텐서 플로우는 기본적으로 3단계를 거친다
1. 그래프를 빌드
2. 그래프를 실행
3. 특정 값들이 업데이트되거나 / 특정 값을 리턴

<그래프>
연결되어 있는 객체 간의 관계를 표현하는 자료구조
node와 edge로 구성되었다
예상하셨겠지만 텐서 플로우는 흐름을 나타내기 때문에 방향 그래프입니다.
즉, 그래프를 빌드하려면 일단 그래프를 만들어야 하고, 이는 노드를 생성한 후 노드끼리 연결하여 관계를 표현해주어야 한다는 뜻
그럼 먼저 노드를 생성해보도록 합시다
노드와 연산
위에서 노드는 연산, "node는 mathmatical operation을 나타낸다"라고 했었다.
텐서 플로우 상에서 노드를 생성하는 법은 다음과 같다.
노드명 = tf.해당 노드의 연산(노드명1, 노드명2)

노드를 생성했고, 그 노드는 연산이라는 것을 알 수 있다.
이제 3가지 노드에 대해서 알아볼 것이다
상수 노드(Constant) / 변수 노드(Variable) / 치환자 노드(Placeholder)에 대해서 알아볼 것이다
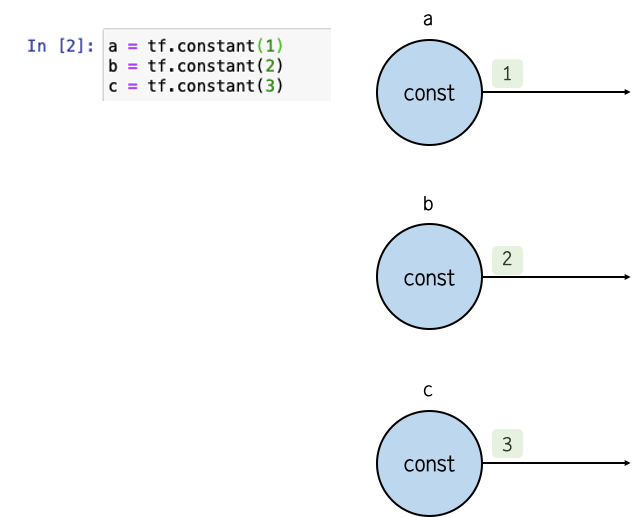
상수 노드(Constant)
상수 노드를 생성하는 명령어는 다음과 같다.
tf.constant( value , dtype=None, shape = None, name="원하는 이름" )
4가지 중 value는 필수, 나머지는 optionvalue : 상수값
dtype : 텐서의 원소들의 값의 데이터형 , 생략되어 있으면 텐서 플로가 자동으로 데이터 타입을 추측함.
텐서 플로가 제공하는 데이터 타입에는 이런 것들이 있습니다.
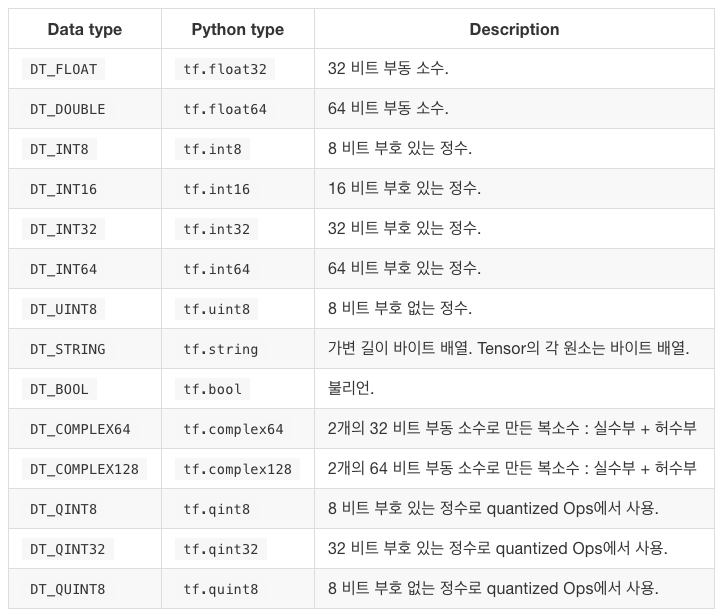
주로 tf.float32와 tf.int32를 사용한다고 합니다.
shape : 결괏값 텐서의 차원(위에 자세히 있습니다) , 생략되어 있으면 value의 shape을 그대로 사용
name : 텐서 플로우를 시각화한 텐서 보드에서 사용할 노드의 이름
# Constant 1-D Tensor populated with value list.
tensor = tf.constant([1, 2, 3, 4, 5, 6, 7]) => [1 2 3 4 5 6 7]
# Constant 2-D tensor populated with scalar value -1.
tensor = tf.constant(-1.0, shape=[2, 3]) => [[-1. -1. -1.]
[-1. -1. -1.]]
상수 노드를 생성할 경우 data flow graph는 다음과 같다
변수 노드
변수는 계속 값이 변하기 때문에, 값이 업데이트되는 수에 사용되는데,
그렇기 때문에 딥러닝 모델에서 파라미터(weight)나 bias처럼 계속 변화하는 수를 변수로 생성합니다.
한 그래프가 실행될 때, 인스턴스화 되고 그 후에 사라지는 일반적 텐서와 달리 변수들은 다수의 그래프 실행에도 살아남는다(업데이트되므로)
변수의 특징 3가지
- 변수가 처음 사용되기 전에 명시적 초기화 필요
- 최적 파라미터를 탐색하므로 반복 시마다 변수를 수정하는 경사 법을 사용할 수 있음
- 추후 사용을 위해 변수에 저장된 값을 디스크에 저장하고 다시 불러올 수 있음(다수의 그래프 실행에도 유지됨)
변수의 사용은 2단계로 정의할 수 있다
- 변수를 생성
- 메서드를 사용하여 세션에 초기화 연산을 수행하며, 변수에 메모리를 할당하고 초기값을 설정
단계별로 알아보자.
1. 변수 생성
먼저 변수를 생성하는 명령어는 tf.Variable()이다.
변수노드 명 = tf.Variable(<initial_value>,name="원하는 이름")
변수노드 명 = tf.Variable(<initial_value>,name="원하는 이름", trainable = False / True)
#trainable : 학습될 수 있는지 없는지를 표현
<initial_value>에 들어갈 수 있는 초기화 함수에는 이러한 것들이 있다
| 초기화 함수 | 설명 |
| tf.zeros(shape, dtype=변수타입 , name="원하는 이름") | shape에 지정한 형태의 텐서를 만들고, 모든 원소의 값을 0으로 초기화 |
| tf.ones(shape, dtype=변수타입 , name="원하는 이름") | shpae에 지정한 형태의 텐서를 만들고, 모든 원소의 값을 1로 초기화 |
| tf.random_normal(shape, mean=평균, stddev=표준편차,dtype=변수타입 , name="원하는 이름") | 정규분포르 따르는 난수를 생성 |
| tf.truncated_normal(shape, mean=평균, stddev=표준편차,dtype=변수타입 , name="원하는 이름") | 절단 정규분포(평균을 기준으로 표준편차보다 크거나 작은 데이터를 제외함)를 따르는 난수 |
| tf.random_uniform(shape, minval=최소값, maxval=최대값,dtype=변수타입 , name="원하는 이름") | [minval, maxval) 구간의 균등분포의 값을 생성 |
빨간색은 필수 입력값입니다. 나머지는 선택
이를 통해 Variable을 생성하면, 이는 텐서가 아니라 하나의 객체가 인스턴스화 된 것이므로,
Variable클래스의 인스턴스가 생성되는 것뿐이라 초기화 단계가 꼭 필요하다
2. 변수 초기화
이를 호출하기 전에는 그래프의 상태는 각 노드에 값이 없는 상태를 의미한다.
해당 함수를 사용해야 Variable의 값이 할당되는 것이고 텐서로서 작동할 수 있게 된다.
어떤 텐서 플로 변수를 사용하기 전에 변수가 요구한 값으로 적절하게 초기화되도록 해야 하는데
그에 해당하는 연산이 바로 tf.assign이다.
초기화 함수는 tf.assign 연산을 이용하여 변수들을 초기화하는 함수이다.
tf.assign
일단 초기화 함수에 대해 알아보기 전에 tf.assign에 대해 설명하도록 한다

위의 코드를 실행한다고 했을 때, 우리는 변수 a = 1이었던 것이 a = 2로 변경될 것을 기대하지만,
실제로 실행해보면 새로운 변수 a가 생겨난 것을 볼 수 있다. (텐서 플로우 내에서 구분을 위해 a_1라고 했을 뿐 둘 다 a라는 이름을 가졌다)
둘 다 같은 a이지만 다른 객체를 참조하고 있는 것이다.
그렇다면 우리가 정말로 원했던 예상 결과처럼 만들어주려면 어떻게 해야 할까? 이때 사용하는 것이 바로 tf.assign이다
tf.assign(변수 텐서명, 새로운 값) # 꼭 세션에 대해서 run해주어야 한다위를 실행해 주면 원하는 결과를 얻을 수 있다

새로운 변수가 생성된 것이 아니라 값이 바뀐 것(변수가 초기화)을 볼 수 있다.
초기화
초기화 방법에는 3가지가 있는데
1) 모든 변수를 초기화
tf.initialize_all_variables() //이전버전
tf.global_variables_initializer() //현재버전그래프 내 모든 연산(노드)에 tf.assign연산*을 작동시켜 이들을 전부 초기화시킨다.
2) 특정 변수를 초기화
tf.initialize_variables(var1, var2, ...)이 방법을 사용하면 선택적으로 특정 변수들만 초기화할 수 있다
3) 다른 변숫값을 참조하여 초기화
참조할 변수 노드명.initialized_value()
이 방법을 이용하면 해당 변수를 다른 변수를 이용해 초기화할 수 있다.
예제를 보면 이해가 갈 것
# 랜덤 값으로 새로운 변수 초기화
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35), name="weights")
# weights와 같은 값으로 다른 변수 초기화
w2 = tf.Variable(weights.initialized_value(), name="w2")이렇게 weights 변수를 이용하여 같은 값으로 다른 변수를 초기화시킬 수도 있다.
이제 마지막 placeholder에 대해 알아보기 전에 텐서 플로의 연산을 알아보자
이미 위에서도 노드에 대해 이야기하고 data flow graph를 예시로 들어서 연산이 무엇인지 노드가 무엇인지
대충 알고 있을 것이다.
3.5 텐서 플로의 연산
연산이라고 하면 보통 수학적 연산만으로 착각하기 쉽다 + , * 등등
하지만 텐서 플로 연산은 노드라고 했던 만큼, tf.constant도 tf.Variable도 연산(노드) 임을 위에서 보았다.
큰 그림에서 보면, 텐서 플로 연산은 계산 그래프에서 텐서에 적용하는 추상적 변환을 나타낸다.
특징
- 커널을 여러 개 가질 수 있음 (CPU / GPU로 구별 가능)
- 연산을 유추할 수 있는 속성을 가짐 ( 연산에도 이름을 제공할 수 있음 ex. tf.add( a, b , name="addition_of_a_and_b") 가능
사용 가능한 종류의 연산을 간단히 소개하면 이러하다

*stateful operation : 상태 저장 연산
연산을 어떻게 쓰는지 자세히 알고 싶으면 추천 참고사이트
https://tensorflowkorea.gitbooks.io/tensor flow-kr/content/g3 doc/api_docs/python/math_ops.html
3.6 placeholder 텐서
학습을 시키거나 테스트하는 동안 어떻게 입력을 딥 모델로 전달하는가?
한 개의 변수는 한 번만 초기화되는 것을 의미하므로 입력을 전달하기 충분하지 않다.
계산 그래프가 한번 실행될 때마다 값을 채울 수 있는 구성요소가 필요하다.
답은 바로 placeholder라는 구조체이다
tf.placeholder(dtype, shape=None, name=None)데이터를 입력받을 수 있는 비어있는 변수라고 생각하는 것이 쉽다.
placeholder는 shape를 유동적으로 지정할 수 있다.
None으로 지정되면, 모든 크기의 데이터를 받을 수 있다.
하지만 주로 batch size에 해당하는 행 부분은 None(유동적)으로 , 데이터 Feature의 길이 (열)은 고정으로 받는다.
책에 나온 예제를 설명해보겠습니다.
x = tf.placeholder(tf.float32, name="x", shape=[None, 784] # ? x 784의 행렬
W = tf.Variable(tf.random_uniform([784,10],-1,-1), name = "W")
multiply = tf.matmul(x,W)
x는 placeholder으로, W는 Variable로 만들어졌습니다.
위에서 placeholder는 입력값을 주로 표현하고, Variable은 가중치나 bias를 주로 표현한다고 했었죠
또한 이름도 x, W인 것을 보니 뉴런 하나의 z = x·W를 계산하고 싶은 모양입니다.
Bias는 존재하지 않는 것으로 가정한 것 같네요
잠깐 일 단원으로 돌아가 봅시다.

그림을 보시고 기억이 나셨으면 좋겠습니다. 바로 여기의 z(b=0)을 구하려는 모양입니다.
여기서의 W는 vector(행렬로는 1 x n)인데요?
가중치가 784 x 10의 행렬로 나타내어졌군요
그렇다면 또 하나 기억나는 게 있으셨으면 좋겠습니다.
1.6 전방향 신경망에서 "신경망을 수학적으로 연속된 벡터와 행렬 연산으로 표현할 수 있다"라는 구절입니다.

여기서 하려는 것은 저 동그리 미 1번까지인 것 같네요
그런데 저희가 가진(텐서 코드에서) input값 x는 행렬인데요?? 그 답은 이미 나왔습니다.
제가 텐서에 대해 설명드릴 때, (위쪽으로 돌아갔다가 오시는 걸 추천)
mini-batch를 이용하기 때문에 1개의 문장이 아닌 3개의 문장을 미니 배치의 크기 (데이터의 부분집합)으로 하여 학습시켜
행렬로 표현된 문장을 -> 3개의 문장(3개의 행렬)을 하나의 3 Tensor로 묶어서 학습시켰다는 말을 써놨을 것입니다.
또한, placeholder에 대해 처음 설명할 때도, "batch size에 해당하는 행 부분은 None(유동적)으로"라는 말을 했습니다.
즉, 사실 하나의 예제만을 학습시킨다면 위의 그림(1.6)처럼 x(벡터 or 1x784 행렬)·W(784x10 행렬) 이 되었겠지만,
이들을 미니 배치 경사 하강법을 이용해? 개의 input x를 행렬로 만들어
x가? x 784의 행렬이 된 것이죠.
좀 멀리 왔는데 이해가 되셨을 거라고 생각하고 , 다시 코드로 돌아오면
x = tf.placeholder(tf.float32, name="x", shape=[None, 784] # ? x 784의 행렬
W = tf.Variable(tf.random_uniform([784,10],-1,-1), name = "W")
multiply = tf.matmul(x,W)
즉, x는 float32 데이터 타입으로 저장된 미니 배치로 만들어진 input 값들이 되겠네요
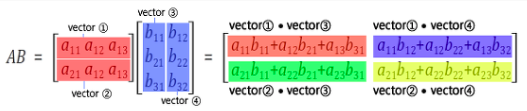
shape = [None , 784] 2개로 표현되었으니 2 Tensor 즉 행렬이고? x 784의 행렬이 될 것입니다.
x의 열수와 W의 행수가 같으니 행렬곱(matmul)이 가능하고요
결국 이렇게 되겠네요

<행렬의 곱>
계산 그래프가 처음 만들어질 때 변수 초기화가 필요한 것처럼
placeholder도 계산 그래프가 실행될 때마다 초기값이 채워져(feed_dict이용)야 한다. (다음 절에서 알아보자)
(즉, 값을 입력해 주어야 한다.)
3.7 텐서 플로의 세션(Session)
위에서는 session을 사용하는 코드를 보여드리면서도 설명하지 않고 넘어왔습니다.
당연히 의문이 생기셨을 것입니다.
위쪽에 나왔던 코드를 다시 가지고 왔습니다.

print(a)하면 1, 2가 나와야 하는 거 아닌가..? 저게 뭐여 라는 의문이 드실 수 있습니다.
이는 바로 Session을 시작해주지 않았기 때문인데요.
왜 이러한 <tf.~~ 어쩌고~~> 하는 문자열이 출력되냐면, 텐서 플로에서 데이터 처리 단위는 텐서(다차원 배열의 객체)이기 때문입니다.
session을 생성하지 않아 flow가 만들어지지 않았고 따라서, 현재 정의되어 있는 노드의 상태가 출력된 것입니다.
import tensorflow as tf
a = tf.constant(1)
b = tf.constant(3)
c = tf.add(a,b)

이런 코드를 짜 이런 계산 그래프를 만들었다고 해봅시다.
우리는 이 계산 그래프를 짜기 위해 tf.constant()와 tf.add()라는 연산을 이용했지만,
실제로는 연산을 수행한 것이 아닌 텐서 객체를 만들어 그래프를 정의한 것입니다.
연산을 수행하려면 a, b에 데이터를 넣어서 flow흐름이 이루어지도록 해야 하는데, 그것을 담당하는 동작이 바로 세션(Session)입니다.
Session은
- 초반 그래프 생성을 담당( 파이썬 객체, 데이터와 객체의 메모리가 할당되어 있는 실행 환경 사이를 연결 )
- 모든 변수를 적절하게 초기화(위에서 tf.assign은 꼭 세션에 대해 run 해주어야 한다고 언급)
- 계산 그래프를 실행 (session객체의 run() 메서드)
하는데 이용이 가능합니다.
책에 있는 예제를 살펴봅시다
import tensorflow as tf
from read_data import get_minibatch()
x = tf.placeholder(tf.float32, name="x", shape=[None, 784])
W = tf.Variable(tf.random_uniform([784, 10], -1, 1), name = "W")
b = tf.Variable(tf.zeros([10]), name = "biases")
output = tf.matmul(x,W) + b
init_op = tf.global_variables_initializer()
#초반 그래프 생성(flow를 만들어줌)
sess = tf.Session()
#모든 변수를 초기화
sess.run(init_op)
feed_dict={"x" : get_minibatch()}
#(부분) 계산그래프 실행
sess.run(output, feed_dict=feed_dict)여기서 read_data는 실제로 존재하는 파이썬 라이브러리가 아니므로
그냥 get_minibatch()는 입력 데이터를 session에 제공하는 것에 의의가 있다고 생각하고 신경 쓰지 않아도 괜찮음
부분 계산 그래프의 실행
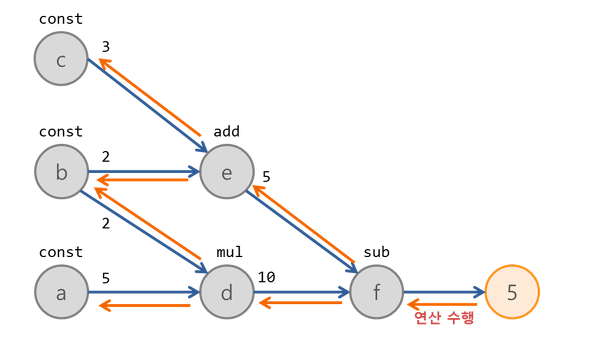
sess.run(연산노드)를 입력하면 해당 연산 노드가 실행된다
입력한 연산 노드에서 시작해서 역방향으로 의존관계에 따라 모든 노드의 연산을 수행한다.
예를 들어 이 그래프에서
sess.run(f)를 수행하면,
부분 그래프의 실행이라는 것을 더 직관적으로 알기 위하여
sess.run(d) 을 수행하면

이렇게 될 것이다.
그럼 위에서 남겨 두었던 placeholder초기화(feed_dict)에 대해 알아봅시다.
feed_dict
placeholder는 입력값으로, 입력값이 전달되어야 해당 노드를 실행할 수 있다.
그때 사용하는 것이 feed_dict인데 session.run과 함께 이용한다.
해당 placeholder인 노드에 값을 전달해주기 위해
sess.run(실행하려는 연산노드 , feed_dict= 입력값으로 넣을 값)이렇게 사용한다.
sess.run을 통해 계산 그래프를 따라 역방향으로 진행하고, 모든 placeholder변수가 feed_dict로 채워진 식별된 하위 그래프에 속해있는지 확인한 후, 원래 인수(argument)들을 평가하기 위해 하위 그래프를 역으로 따라 올라가며 모든 중간 연산을 실행한다.
feed_dict={"x" : get_minibatch()}
#(부분) 계산그래프 실행
sess.run(output, feed_dict=feed_dict)위와 같이 값을 전달하여 output노드를 실행한 것을 볼 수 있다.
이제 계산 그래프를 작성하고 관리할 때 중요한 개념 2가지를 살펴보도록 한다
3.8 변수 범위 탐색과 변수 공유
복잡한 모델을 만들 때, 인스턴스화 하고 싶은 변수들의 큰 집합을 한 곳에서 함께 재사용하고 공유해야 할 때가 많다.
다음 함수를 살펴보자
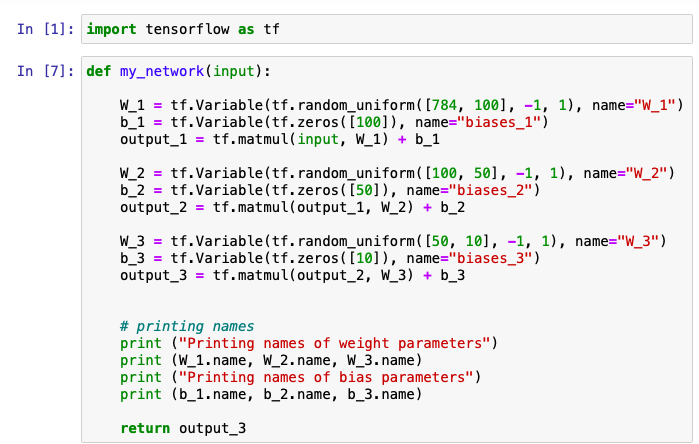
def my_network(input):
W_1 = tf.Variable(tf.random_uniform([784, 100], -1, 1), name="W_1")
b_1 = tf.Variable(tf.zeros([100]), name="biases_1")
output_1 = tf.matmul(input, W_1) + b_1
W_2 = tf.Variable(tf.random_uniform([100, 50], -1, 1), name="W_2")
b_2 = tf.Variable(tf.zeros([50]), name="biases_2")
output_2 = tf.matmul(output_1, W_2) + b_2
W_3 = tf.Variable(tf.random_uniform([50, 10], -1, 1), name="W_3")
b_3 = tf.Variable(tf.zeros([10]), name="biases_3")
output_3 = tf.matmul(output_2, W_3) + b_3
# printing names
print "Printing names of weight parameters"
print W_1.name, W_2.name, W_3.name
print "Printing names of bias parameters"
print b_1.name, b_2.name, b_3.name
return output_3
대충 이런 작업을 수행해 주는 함수 일 것이다.

이 작업을 함수로 만들었다는 것은
위와 같은 작업을 여러 번 수행하고 싶다는 의미일 텐데
실제로 함수를 2회 수행해보자.

우리는 W와 b variable을 표본을 제공할수록 학습되어 업데이트되기를 바라고 실행했는데,
위의 결괏값을 보면 각각 6개의 변수 W_1, W_2, W_3, b_1, b_2, b_3에 대한 사본이 생성되어 실행된 것을 볼 수 있다.
위에서 tf.assign을 설명했을 때와 유사해 보인다.
이를 해결하기 위해, 변수를 공유할 때는 다음 두 함수를 이용해 변수 범위 지정을 해 준다
tf.get_variable(<name>,<shape>, <initializer>)
tf.variable_scope(<scope_name>)
tf.get_variable(<name>, <shape>, <initializer> )
입력된 이름의 변수를 생성하거나 반환한다.
해당 이름을 가진 변수가 존재하는지 확인하여, 변수가 존재한다면 반환하고, 변수가 없으면 shape와 initializer로 생성한다.
존재한다면 반환하니 같은 이름의 변수에 대하여 새로운 사본이 생성되지 않게 해 준다
tf.Variable 값을 직접 전달하여 변수를 생성하는데, tf.get_variable은 직접 값을 전달하는 대신 initializer를 사용한다.
shape는 이미 알고 있을 태니, initializer에 대해 설명하도록 한다.
< initializer >
initializer는 shape를 가져와서 텐서를 제공하는 함수이다.
| Initializer함수 | 설명 |
| tf.constant_initializer(value) | value값으로 모든 것을 초기화 |
| tf.random_uniform_initializer(minval, maxval) | [minval, maxval)구간의 균등분포로 값을 초기화 |
| tf.random_normal_initializer(mean, stddev) | 정규분포를 따르는 난수를 생성하여 초기화 |
이제 맨 처음에 책에 있는 예제를 이를 이용해서 바꾸어보면 다음과 같다
def layer(input, weight_shape, bias_shape):
weight_init = tf.random_uniform_initializer(minval=-1,maxval=1)
bias_init = tf.constant_initializer(value=0)
W = tf.get_variable("W", weight_shape, initializer=weight_init)
b = tf.get_variable("b", bias_shape, initializer=bias_init)
return tf.matmul(input, W) + b
이렇게 tf.get_variable을 이용하여 가중치 W와 bias b 변수를 구현하면,
새로운 사본이 생성되지 않을 것이다.
tf.variable_scope(<scope_name>)
tf.get_variable()이 작동하는 범위를 결정하고, tf.get_variable()에 전달된 이름의 "이름 공간(namespace)"를 관리한다.
이름 공간(namespace)
저는 c++을 아직 공부 중이라서 namespace에 대해서 몰라서 적어보았습니다.
c++에서의 namespace개념과 유사하다고 하네요
윤성우 열혈 C++ 프로그래밍 책에 namespace부분을 참고했습니다.
이름 공간은 말 그대로 특정 영역에 이름을 붙여주기 위한 문법적 요소로, "이름을 붙여놓은 공간"이라고 생각하면 됩니다.
이 개념이 왜 필요할까?
위의 코드 예로도 눈치채신 분들도 있겠지만 저는 못 챘으므로 책에 나온 쉬운 예를 설명하겠다
프로그램이 대형화되어가면서 이름의 충돌 문제가 많아졌다.
어떤 대학교에서 매우 큰 시스템을 개발이 필요하게 되어, 3개의 회사가 협력하여 시스템을 개발하기로 했다고 해보자
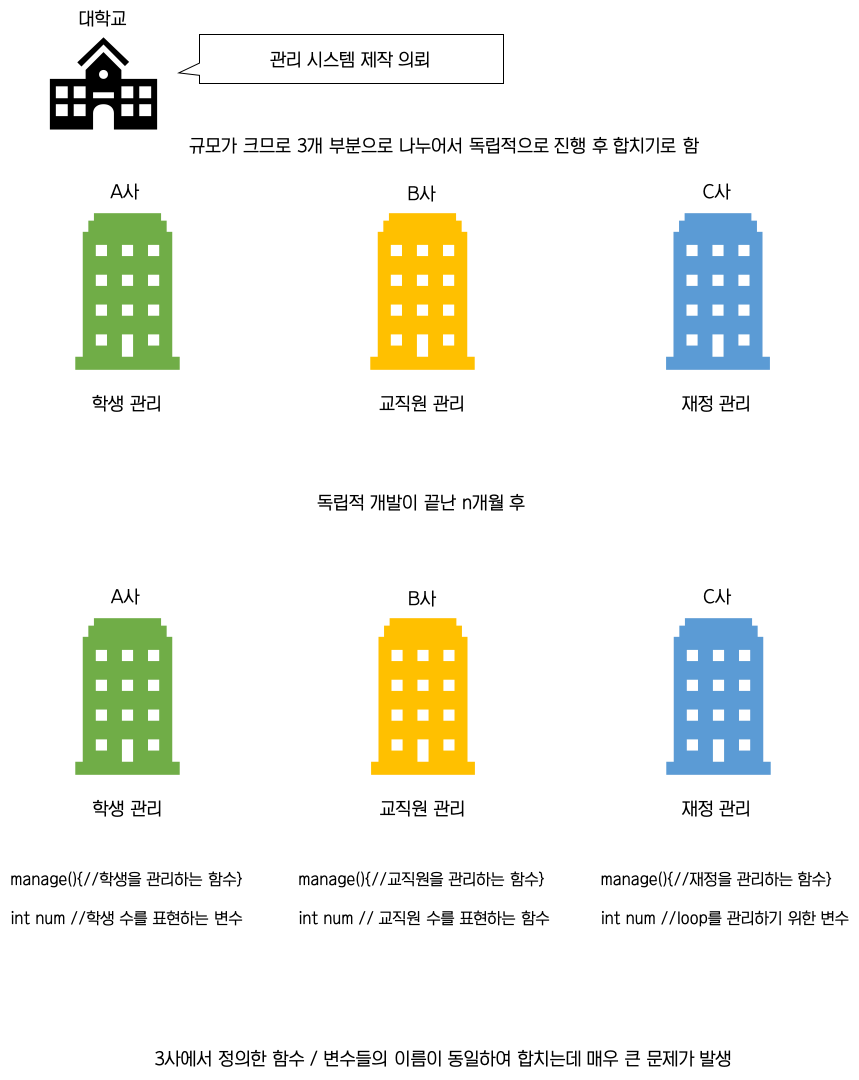
분명 이런 문제가 생길 거다 친구랑 같은 과제만 해도 같은 이름의 변수가 생기는데...
그렇다면 어떻게 이 문제를 해결할까?
설마 3사가 어떤 함수가 만들어질지도 모르는데 미리 함수 및 변수의 이름을 전부 정해서 충돌을 막는 방법을 사용하겠는가?
그래서 "이름 공간(name space)"라는 개념이 생겨났다.
ㅇㅇ 대학교 컴퓨터공학과에 "Jason"이라는 학생이 두 명이라고 해보자
그럼 누군가 제이슨을 불렀을 때, 둘 중 누구를 부르는지 헷갈릴 것이다
그렇다면 이들을 어떻게 구별하는가? 여러 가지가 있겠지만 둘의 학번이 다르니
20학번 Jason , 18학번 Jason이라고 하면 아무도 둘을 헷갈리지 않을 것이다.
이름 공간은 바로 이런 원리다
18학번(namespace) / Jason(Variable)
그렇다면 텐서 플로에서는 어떤 방법으로 namespace를 부여해서 같은 이름의 변수들을 구분할까
(참고로 변수를 만들 때 name부분을 쓰지 않는다고 해서 해당 변수가 name을 가지지 않는 것이 아니고 자동으로 지어진다
Variable, Variable_1 등등으로...)
4종류가 있다고 하는데 그중 하나가 지금 나온 함수인 tf.variable_scope이다
다음 텐서 플로 코드를 보자
with tf.variable_scope("scope1"):
v1 = tf.get_variable("v1", 1, initializer=tf.constant_initializeer(1.))
v2 = tf.get_variable("v2", 1, initializer=tf.constant_initializeer(2.))다음 코드와 같이 tf.variable_scope("scope1"): 의 영향력 내에서
tf.get_variable()을 통해 만들어진 변수 v1, v2는 단순한 v1, v2가 아니라
namespace를 포함하여 scope1/v1 , scope1/v2라는 값을 name으로 가지게 된다
v1.name = scope1/v1
v2.name = scope1/v2라는 의미
+) 추가
get_variable()뿐만 아니라 tf.Vairiable()로 만들어진 변수에도 동일하게 namespace가 적용된다.
get_variable()로 만든 변수에는 namespace를 주지 않고, tf.Variable()로 생성된 변수에만 namespace를 주고 싶으면 tf.name_scope()를 사용한다.
이제 맨 처음 책에 나온 예제를 다음의 함수를 이용해 고치면 다음과 같다
def my_network(input):
with tf.variable_scope("layer_1"):
output_1 = layer(input, [784, 100], [100])
with tf.variable_scope("layer_2"):
output_2 = layer(output_1, [100, 50], [50])
with tf.variable_scope("layer_3"):
output_3 = layer(output_2, [50, 10], [10])
return output_3
이제 맨 처음 나온 함수와 바뀐 함수의 실행결과를 비교해봅시다
<바뀌기 전 함수>
def my_network(input):
W_1 = tf.Variable(tf.random_uniform([784, 100], -1, 1), name="W_1")
b_1 = tf.Variable(tf.zeros([100]), name="biases_1")
output_1 = tf.matmul(input, W_1) + b_1
W_2 = tf.Variable(tf.random_uniform([100, 50], -1, 1), name="W_2")
b_2 = tf.Variable(tf.zeros([50]), name="biases_2")
output_2 = tf.matmul(output_1, W_2) + b_2
W_3 = tf.Variable(tf.random_uniform([50, 10], -1, 1), name="W_3")
b_3 = tf.Variable(tf.zeros([10]), name="biases_3")
output_3 = tf.matmul(output_2, W_3) + b_3
# printing names
print "Printing names of weight parameters"
print W_1.name, W_2.name, W_3.name
print "Printing names of bias parameters"
print b_1.name, b_2.name, b_3.name
return output_3<바뀌기 전 함수의 실행 결과>

<바뀐 함수>
def layer(input, weight_shape, bias_shape):
weight_init = tf.random_uniform_initializer(minval=-1,maxval=1)
bias_init = tf.constant_initializer(value=0)
W = tf.get_variable("W", weight_shape, initializer=weight_init)
b = tf.get_variable("b", bias_shape, initializer=bias_init)
return tf.matmul(input, W) + b
def my_network(input):
with tf.variable_scope("layer_1"):
output_1 = layer(input, [784, 100], [100])
with tf.variable_scope("layer_2"):
output_2 = layer(output_1, [100, 50], [50])
with tf.variable_scope("layer_3"):
output_3 = layer(output_2, [50, 10], [10])
return output_3
<바뀐 함수의 실행 결과>

아래 그래프 그림을 다시 보고 오시면 input으로 들어간 행렬의 행수 x 10의 행렬이 결괏값(shape)으로 나오는 것이 맞고,
Layer 3의 add노드에서 나온 값인 것도 맞네요

맨 위의 그래프와 다른 점은 일단 변수명이 변경되었습니다.
다른 namespace를 가지니 변수명이 같아도 되니 더 보기가 편해졌습니다.
| 변경 전 | 변경 후 |
| W_1 | Layer_1/W |
| b_1 | Layer_1/b |
| W_2 | Layer_2/W |
| b_2 | Layer_2/b |
| W_3 | Layer_3/W |
| b_3 | Layer_3/b |
하지만, 함수를 2회째 실행시켜보면

이미 Layer_1/W라는 변수가 존재한다는 오류가 발생합니다.
(물론 Layer_1/b~Layer_3/b까지 전부 이미 존재하겠지만, 맨 처음 오류난 부분에서 정지된 것 같습니다.)

원래는 금지되어 있지만, 공유를 허용하고 싶으면
tf.get_variable_scope(). reuse_variables()를 사용해주면 공유가 가능해집니다.

공유가 가능해져 오류가 나지 않고 사본이 생긴 모습을 볼 수 있습니다.
3.9 CPU와 GPU로 모델 관리하기
텐서 플로는 모델을 만들고 학습시키기 위한 다양한 컴퓨팅 기기들을 사용할 수 있게 해 주는데
지원하는 기기는 문자열 ID로 표현되고 일반적으로 다음과 같다
| 문자열ID | 지원기기 |
| "/cpu:0" | 컴퓨터 CPU |
| "/gpu:0" | GPU가 하나일 경우, 컴퓨터의 첫번째 GPU |
| "/gpu:1" | GPU가 또 하나 더있을 경우, 컴퓨터의 두번째 GPU |
텐서 플로 연산이 CPU와 GPU 커널이 모두 있고 GPU 사용이 가능할 때, 텐서 플로는 자동으로 GPU구현 코드를 사용합니다
저도 GPU를 사용할 수 있도록 설치하고 싶었으나...
텐서 플로나 케라스에서 공식적으로 지원하는 기능으로 tensor flow-gpu를 사용하기 위해서는 NVIDIA의 GPU모델이 장착되어야만 지원이 가능하다고 하더라고요
저는 Intel사의 GPU가 장착되어있어서 불가능했습니다.
물론 뭐 OpenCL/plaidML 등을 통해 사용이 가능하다고 하긴 하는데
구글에서 제공하는 colab을 사용하시면 gpu가 없더라도 돌릴 수 있습니다.
계산 그래프가 어떤 장치들을 사용하는지 검사하기 위해 log_device_placement를 True로 설정하여 세션을 초기화합니다.
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
또한, 특정 기기를 지정하여 사용하고 싶을 때는 tf.device를 통해 장치를 선택할 수 있습니다.
하지만 선택한 장치가 사용할 수 없을 경우에는 오류가 발생하므로, 장치가 존재하지 않을 때 텐서 플로가 자동으로 사용 가능한 다른 장치를 찾게 할 수도 있습니다.
위의 코드에서 allow_soft_placement=True로 설정해서 전달하면 됩니다.
with tf.device('/gpu:2'):
a = tf.constant([1.0, 2.0, 3.0, 4.0], shape=[2, 2], name='a')
b = tf.constant([1.0, 2.0], shape=[2, 1], name='b')
c = tf.matmul(a, b)
sess = tf.Session(config=tf.ConfigProto( allow_soft_placement=True, log_device_placement=True))
sess.run(c)3번째 gpu를 사용해서 코드를 돌리되, 존재하지 않을 때는 자동으로 사용 가능한 다른 장치를 이용해 돌리는 코드입니다.
또한, 텐서 플로는 타워 방식(tower-like fashion)이라는 모델을 작성해 여러 GPU를 사용하도록 모델을 만들 수 있습니다.
colab을 이용하면 GPU가 없어도 돌릴 수 있습니다

* 아 참 colab은 tensorflow ver2를 사용하는듯 합니다
버전 2에서는 Session()이 사라졌고요
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))이 함수도
sess = tf.compat.v1.Session(config=tf.compat.v1.ConfigProto(log_device_placement=True))이렇게 변경되었다고 하니 참고 부탁드립니다
텐서플로우 버전1과 버전2가 얼마나 달라졌나 궁금하신 분들은 lv99.tistory.com/38
이 분이 자세히 설명해주셨더라고요. 훨씬 좋고 쉽고 간결해진 것 같은데 전교수님이 이 책을 쓰라고 하셔서... 선택권이 없습니다
자료의 양이 아직은 버전1이 더많은것도 사실이고요
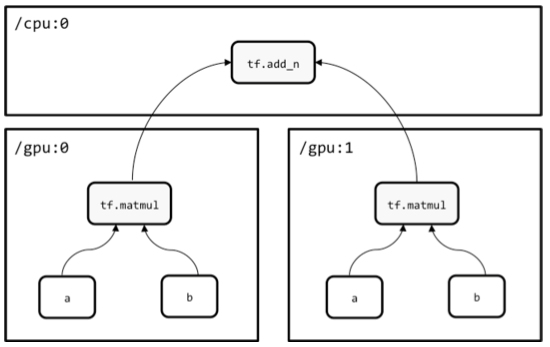
for문을 이용해 한 번은 GPU0로, 한번은 GPU1로 실행한 후 두 값을 c에 append 하여
CPU상에서 sum을 구해준 다음과 같은 계산 그래프입니다.
for문 1회 시행했을때 tf.matmul(a,b) 는 [5.0 ,11.0] 이고 이를 2회돌려서 append 했으니 2개겠고

CPU에서 둘을 더해줬으니 [10.0 22.0] 이 맞네요

shape = (2,1) 인건 아시겠죠
여러 GPU를 사용한 모델의 예였습니다.
NDIVIA GPU가 없어서 설치도 못했는데 한번 돌려봤습니다 (헛짓거리)

뭐 역시나 안됐다고 합니다

넌 사용 불가능하다고 친절하게 알려주네요
<참고자료 - 두 게시글 참고자료가동일 >
https://www.youtube.com/watch?v=m0qwxNA7IzI
m.blog.naver.com/sundooedu/221195984077
딥러닝[Deep Learning]프레임워크 , 상위 10가지
지금은 바로 인공지능(AI)시대 이다. 머신러닝 및 예측분석은 이제 거의 모든 현대 비즈니스에 수립되고 ...
blog.naver.com
TensorFlow #004 TensorFlow 의 상수, 변수, 치환자 3부
Python 은 상수가 없다. 하지만 텐서플로우는 상수 텐서를 써야하는데... Python 은 상수가 없다. 위에 코드를 보면 a 라고 하는 식별자에 텐서플로우의 상수를 2번 대입하는 것을 볼 수 있다. 하지만
expert0226.tistory.com
[러닝 텐서플로]Chap03 - 텐서플로의 기본 이해하기
Chap03 - 텐서플로의 기본 이해하기 텐서플로의 핵심 구축 및 동작원리를 이해하고, 그래프를 만들고 관리하는 방법과 상수, 플레이스홀더, 변수 등 텐서플로의 '구성 요소'에 대해 알아보자. 3.1 ��
excelsior-cjh.tistory.com
https://tensorflowkorea.gitbooks.io/tensor flow-kr/content/g3 doc/api_docs/python/constant_op.html
상수, 시퀀스, 난수 생성 · 텐서플로우 문서 한글 번역본
No results matching ""
tensorflowkorea.gitbooks.io
텐서플로우(Tensorflow) 기본 문법 - Variable
텐서플로우 Variable 에 대해서 알아보겠다. 아래의 코드는 각 변수에 5, 10, 3 을 할당하며 기본적으로 텐서의 정보가 반환이 될 것이라고 예상하는 코드이다. 그리고 이를 출력한다면? 1 2 3 4 5 6 7 v
gdyoon.tistory.com
blog.naver.com/PostView.nhn?blogId=ndb796&logNo=221278249999
10. 텐서플로우(TensorFlow) 세션(Session)
기존에 파이썬이나 C++만 공부하던 사람은 텐서플로우를 처음 접했을 때 다양한 오류 메시지를 만나게 됩...
blog.naver.com
name_scope, variable_scope
c++ namespace와 같은 기능을 하는 것이 TF는 크게 name_scope와 variable_scope가 있다. 정확히는 4종류가 있지만 여기서는 가장 많이 쓰이는 두 가지만 다룬다. 1. auto naming and run by name 두 종류의 scope..
eyeofneedle.tistory.com
everyday-deeplearning.tistory.com/entry/파이썬으로-딥러닝하기-손실함수-평균제곱오차MSE-교차-엔트로피-오차CEE
파이썬으로 딥러닝하기 | 손실함수 평균제곱오차(MSE) & 교차 엔트로피 오차(CEE)
안녕하세요! 오늘은 손실함수에 대해 알아보도록 하겠습니다!! 손실함수란? 신경망 성능의 '나쁨'을 나타내는 지표로, 현재의 신경망이 훈련데이터를 얼마나 잘 처리하지 '못'하느냐 나타냅니다
everyday-deeplearning.tistory.com
텐서보드 사용법
TensorBoard는 TensorFlow에 기록된 로그를 그래프로 시각화시켜서 보여주는 도구다. 1. TensorBoard 실행 tensorboard --logdir=/tmp/sample 루트(/) 폴더 밑의 tmp 폴더 밑의 sample 폴더에 기록된 로그를 보겠..
pythonkim.tistory.com
'ML' 카테고리의 다른 글
| [딥러닝의 정석] 05. 합성곱 신경망-1 (0) | 2020.08.02 |
|---|---|
| [딥러닝의 정석] 04. 경사 하강법을 넘어서 (0) | 2020.07.27 |
| [딥러닝의 정석]03. 텐서플로로 신경망 구현하기-2 (0) | 2020.07.21 |
| [딥러닝의 정석]02. 전방향 신경망 학습 (0) | 2020.07.12 |
| [딥러닝의 정석] 01. 신경망 (0) | 2020.07.06 |



