RNN에 대한 내용입니다
이 또한 완성하지 못했네요.. 일단 내용도 어렵고 책에있는 코드도 안돌아가고
7.13은 3일은 돌려야하는 코드라고 하던데 사실상 제가 해보기엔 많이 불가능해보이네요
돌리는동안 꺼질듯..
5단원 CNN으로 과제가 있기때문에 7단원은 끝까지 공부하기 어려울것 같네요
일단 최대한 해보려고하는데 미뤄뒀다가 한부분까지만 일단올리도록..결정햇습니다
7.15 요약
시퀀스 분석
- 시퀸스 분석에서의 전방향 신경망 / 순환신경망
- 언어 응용 분야에서 주의집중 동작 방식의 활용
7.1 가변 길이 입력 분석하기
지금까지는 고정 크기 데이터로만 작업했다 (MNIST 28*28)
이 모델들은 매우 강력하지만, 고정 길이 모델로 충분하지 않을 때가 많다.
일상 생활에서 이루어지는 대다수 상호작용은 시퀀스*들(순서가 있는)에 대한 깊은 고민이 필요하다.
가변 길이 입력에 적응하려면 딥러닝 모델을 어떻게 설계할지에 대한 고민이 필요하다.
시퀀스 데이터
순서가 있는 데이터로 시퀀스 원소들끼리 특정 순서를 가지므로 독립적이지 않음
예) 시계열 데이터(시간의 흐름에 따라 기록된 데이터)
텍스트 데이터( 텍스트를 쪼개면 시간에 따라 문맥이 존재하므로 순서가 존재함 )

다음 장에서는 이 문제를 해결하기 위한,
시퀸스를 다루는 전방향 신경망을 조작해 활용할 수 있는 방법과 조작의 한계를 분석하고 새로운 구조를 논의한다.
또한, 인간 수준의 논리적 추론과 시퀀스에 대한 인식을 복제하는 과제 일부를 해결하고자 지금까지 탐구된 가장 진보한 구조를 설명한다.
7.2 신경망 n-gram으로 seq2seq 해결하기
텍스트 본문을 처리하고 품사 태그의 시퀀스를 생성하는 전방향 신경망 구조를 탐색한다.
즉, 입력 텍스트에서 각 단어를 명사, 동사, 전치사 등으로 적절하게 표시하는 것이다.
품사 : 명사/대명사/수사/조사/동사/형용사/관형사/부사/감탄사
영어의 8품사 : 명사/동사/형용사/부사/접속사/전치사/감탄사
한 문장에서 단어가 사용되는 방식의 의미를 이해할 수 있는 알고리즘으로 seq2seq라는 분류문제의 예이다.
이 문제의 목표는 입력 시퀀스를 해당하는 출력 시퀀스로 변환하는 것 이다.

다른 seq2seq문제로는 언어간 텍스트 번역, 텍스트 요약, 음성을 텍스트로 옮기기 등이 있다.
품사 태그들의 전체 시퀀스를 예측하는 데 한 번에 모든 텍스트 본문을 어떻게 취할 수 있을지는 명확하지 않다.
핵심은 이 문제를 해결하기 위해( 어떤 단어의 품사를 예측하기) 장기 의존성*들을 고려할 필요가 없다는 것이다.
장기 의존성(Long Term Dependencies)
은닉층의 과거의 정보가 마지막 까지 전달되지 못하는 현상
(04. 경사 하강법을 넘어서 - Vanishing/Expolding Problem 참고 ) 하고 오시길 바랍니다.
앞쪽의 은닉층의 값이 활성화 함수를 통과하여 전파되는 과정속에서 값이 희미해져 뒷쪽 은닉층은 점점 매우 앞쪽 은닉층의 정보를 알수 없게 되어가는 현상입니다.
이 문제는 RNN에서 자주 언급되는데 예시를 한번 살펴보면,
다음 문장에서 빈칸을 추론하는 모델을 만들었다고 하자.
첫번째 문장으로, 스파이더맨은 방사능 _____에 물렸다. 라는 문장을 집어넣으면,
"거미spider"Man 을 보아 문맥상 빈칸에 거미(spider)가 나오는 사실을 쉽게 납득할 수 있다.

그런데 두번째 문장을 보면, 스파이더맨 이라는 빈칸을 추측하기 위한 가장 핵심적인 단어뒤에 너무나 많은 단어들이 나와,
빈칸이 나올 때 까지 (스파이더맨이라는 단어가)충분히 전달되기 어려워, 빈칸에 거미spider라는 단어를 추측하기 어렵다.
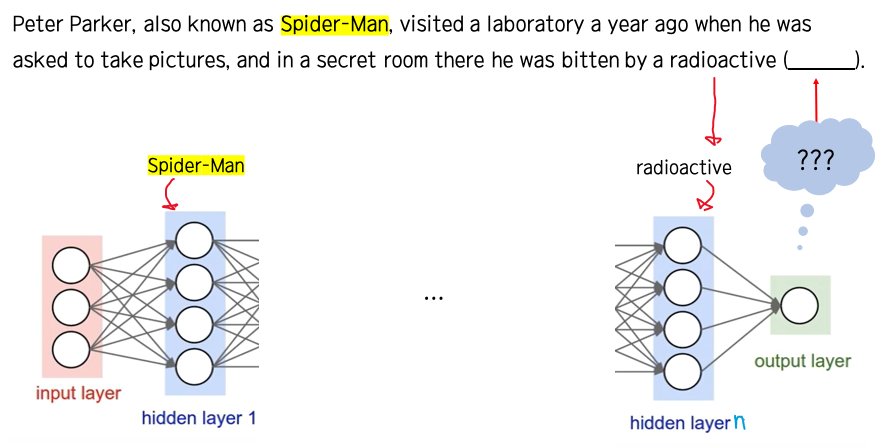
이것이 바로 장기의존성 문제이다
뒷쪽의 작업을 수행하기위해 앞쪽의 작업이 중요한 역할을 하는데, 뒷쪽 레이어에 도달할 수록 더 앞쪽에 존재하는 정보가 흐려지므로 제대로 뒷쪽 작업을 수행할 수 없게 되는 것이다.
그렇다면 다시 이 예제로 돌아와서
이 문제는 왜 장기의존성을 고려할 필요가 없는지 감이 올 것이다.
단어 하나하나의 품사를 파악하는데는 최소 주변의 몇개의 단어만 고려하지 멀리 떨어져 있는 단어들을 고려할 필요가 없기 때문이다.
이 관찰에 내포된 의미는 모든 품사 태그를 예측하는데 전체 시퀀스를 사용할 필요가 없고,
대신 고정 길이 부분 시퀀스를 사용해 각 품사 태그를 한번에 하나씩 예측할 수 있다는 것이다.
특히, 관심단어에서 부터(starting from) 시작해 앞쪽으로 n개의 단어를 확장하는 부분 시퀀스를 사용한다. (extending n words into the past)

입력 i번째 단어에 대한 품사 태그를 예측하기 위해 입력으로 i-n + 1번째 , i - n + 2번째 , ... , i번째(관심단어) n개를 입력으로 사용한다.
이 부분 시퀀스를 "문맥 윈도(Context Window)"라고 한다.
전체 텍스트를 처리해야하므로 텍스트의 맨 처음에 신경망을 배치하는 것으로 시작하여, 입력이 끝날 때 까지 문맥윈도의 가장 오른쪽 단어의 품사태그를 예츠해 한번에 한 단어씩 문맥윈도 이동을 계속한다.
N - gram
확률론적 모델로 고안되어 나온 확률분석 방법중 하나로,
텍스트, 바이너리 등 전체의 문자열을 N개 만큼의 서브 스트링으로 나누어 통계학적으로 사용한 방법
N개로 조각난 문자열을 통해 발생하는 단어의 출현 빈도를 학습(암기)하여 사용한다.
ex) 2-gram

왜 N-gram방법을 사용하는가? (왜 빈도를 따질까)
우리가 자연어로 만들어내는 문장은 정규화 되지 않고 무한하며 복잡한 문법을 따른다.
따라서 컴퓨터가 정확하게 알아채기는 어렵다. 그래서 언어 모델링을 이용하면 분석이 쉬워질 수 있다.
예를들어 발음이 비슷하지만 뜻이 다른 두 문장이 존재한다고 하자.
그 문장중 하나를 음성인식 시켰을 때, 기계는 해당 문장을 듣고 2가지 가능성있는 문장을 도출해낸다.
이때, 빈도를 분석하여 더 많이 사용된 빈도가 높은 문장을 출력하는 것이 정답에 가까울 확률이 높을 것이다.
또한, 그 외에도 빈도를 분석하는 것은 세대의 흐름과 방향을 알 수 있다.
어떤 것이 요즘 사람들이 찾는 빈도가 높은지 향후에는 어떻게 되어갈지 분석할 때 또한 빈도는 큰 도움이 된다.
7.3 품사 태거 구현하기
colab을 사용했습니다. (설정은 여기서)
2020/08/04 - [분류 전체보기] - [Colab]Tensorflow 버전 낮추기
외않되..;
이 장의 나머지 부분에서는 훨씬 더 복잡한 시퀀스 관련 학습 과제들을 생각해 보기로한다.
어려운 문제를 해결하는데 아주 새로운 개념을 도입하고 새로운 구조를 개바래야하며, 현대적 딥러닝 연구에 관한 최첨단 탐험을 시작해야한다.
다음절에서는 의존 구문 분석(dependency parsing)문제를 다루는 것 부터 시작한다.
7.4부터해야겠다
7.4 의존 구문 분석(Dependency Parsing)과 SyntaxNet
문제의 복잡성이 증가하면 seq2seq 문제를 해결하는데 좀 더 창의적일 필요가 있다.
예시로 의존 구문 분석 문제를 살펴보자
의존 구문 분석이란
한 문장에서 단어와 단어 사이의 관계를 mapping하는 것이다.
사실 의존 구문 분석에 대해 자세히 설명하려면 무슨 논문급으로 몇십장에 대해서 원리를 설명할 수도 있을 것이다
물론 난 국어를 못하니까.. 논문을 찾아봐야함..
중/고등학교때 형태소의 정의를 파고들다가 에이포지 두쪽 이상을 넘어갈 때 쯤 그만뒀던 기억이 떠오르니 의존 구문 분석에 대한 이야기는 대충하고 넘어가도록 하자... 우리는 지금 그걸 하려는게 아니니까..
더 알아보고싶다면 아래 자료들을 참고하자
아래 그림과 같이 의존 구문 분석 트리로 만들 수도 있다.

트리를 시퀸스로 표현하는 한가지 방법은 이를 선형화 하는 것이다
예를 들어 위와 같은 트리는
(took, took_I, took_taxi, took, [taxi, taxi_a, taxi_to, a, [to, to_airport, [airport, airport_the, the]]]) 로 표현 가능하다
품사를 고려하면 (took, NSUBJ,DOBJ, took, [taxi, DET, PREP, a, [to, POBJ [airport, DET, the]]]) 로 바꿀 수 있다.
트리를 선형화한 예를 더 살펴보면 다음과 같다

seq2seq문제에 대한 한가지 해석은 입력 시퀸스를 읽어
위와 같이 입력 시퀸스에 대한 의존 구문 분석 트리를 선형화해서 출력(을 토큰들의 시퀸스로 생성)으로 나타내는 것이다.
여러가지 문제점이 있는데,
- 단어들과 그들의 품사 태그 사이에 명확한 일대일 대응이 있어도 이들을 어떻게 이식해야하는지 명확하지 않음
- 문장에서 단어들이 어떻게 정렬되는지와 선형화에서 토큰이 어떻게 정렬되는지 사이에 명확한 관계가없음
- 언뜻 보기에는 이 설정이 어떤 장기 의존성을 고려할 필요가 없다는 가정에 위배되는 것 처럼보임 -> 7.5 빔 탐색 으로..
이 문제에 쉽게 접근하는 방법으로는 "아크-표준 시스템(arc-standard system)"으로 알려진 기술이 있다.
올바른 의존 구문 분석을 생성하는 유효한 동작(action) 시퀸스를 찾아 의존 구문 분석 작업을 재검토하는 기술이다.
이 기술은 한 단계당 3가지의 동작을 수행할 수 있으며,
처음 시작시 스택에 문장의 처음 두 단어를 넣고 버퍼에 나머지 단어를 유지한다
버퍼가 비어있고(모든 단어에 대해 shift) 스택에 하나의 요소(arc로 묶임)가 있을 때 끝난다.
3가지 동작은 다음과 같다
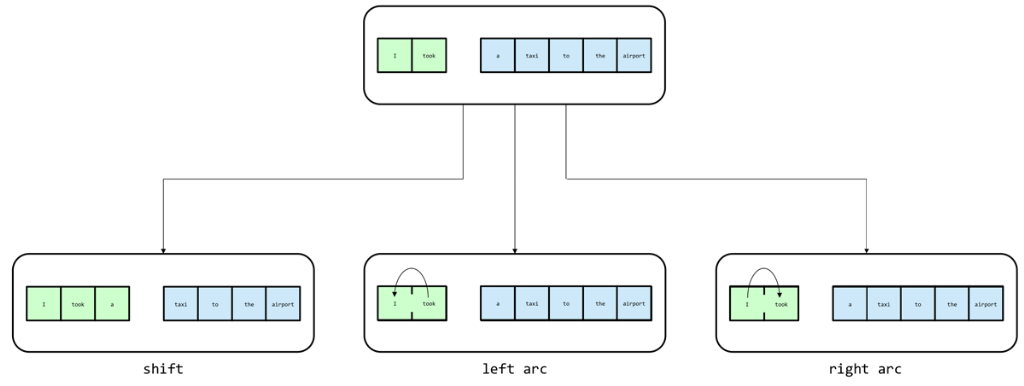
- 이동(shift) : 한 단어를 버퍼에서 스택으로 이동 시킨다.
- 왼쪽 아크(left arc) : 스택 앞의 두 요소를 하나의 단위로 결합한다. 가장 오른쪽 요소의 루트가 부모노드고, 가장 왼쪽 요소의 루트가 자식노드이다.
- 오른쪽 아크(right arc) : 스택 앞의 두 요소를 하나의 단위로 결합한다. 가장 왼쪽 요소의 루트가 부모노드고, 가장 오른쪽 요소의 루트가 자식노드이다.
이를 실제로 실행 한 그림을 보면 다음과 같다.

위와 같은 의사결정은 로직이 아닌 학습 문제로 구성하는데, 그 방법은 다음과 같다
모든 단계에서 현재 구성을 취하고, 구성을 설명하는 특징을 추출하여 구성을 벡터화한다.
특징 구성에는 여러가지가 있을 수 있는데 스택과 버퍼의 특정 위치에 있는 단어들, 그 단어들의 특정 자식들, 품사 태그 등이 있다.
학습 시간동안 이 벡터를 전방향 신경망에 곱하고 다음 동작에 대한 신경망 예측(y)을 언어학자가 만든 황금 표준 결정과 비교한다. (e를 찾는 것?)
실제로 이 모델로 작업하여 나온 결과물을 특징 추출과 동작 예측, 동작 응용 등과 같은 것의 시작점으로 사용할 수 있다.

이 아이디어들은 의존 구문 분석을 위한 최첨단 오픈소스 구현인 구글 Syntax의 핵심 요소가 된다.
위의 방법은 실전에서 SyntaxNet을 배치하기 위한 단순한 전략이다
이 전략은 순수 greedy을 사용한 방법이다.
즉, 그때 그때 현재의 최고 확률의 예측을 선택하지, 지금의 선택이 후에 미칠 수 있는 영향에 대해서는 고려하지 않는다
품사 예제에서 잘못된 예측을 하는 것은 거의 중요하지 않았다.
이것은 각 예측을 순전히 독립적인 하위 문제로 간주하기 때문이다.( 선택이 다음단계에 영향을 주지 않음)
7.5 빔 탐색(Beam Search)과 전역 정규화(Global Normalization)
위에서 언급한 바와 다르게 n단계에서의 예측이 n+!단계에서 사용하는 입력에 영향을 미치므로,
이 가정은 SyntaxNet에서 더는 유효하지 않다.
즉, 우리가 전 단계에서 만들어낸 실수로 인해 이후의 모든 결정에 영향을 미친다는 뜻이다.
더욱이 실수가 명백해지면 그때로 돌아가거나 그 실수를 고치는 좋은 방법은 없다
마치 ..나의 인생과 같군
극단적인 예시로 이를 보여주도록 하겠다
The complex houses married and single soldiers and their families 라는 문장이 있다.

문장을 알맞게 번역하면 다음과 같다
그렇다면 complex는 명사가되고 houses는 동사가된다.
하지만 (사람도 처음 봤을 때 헷갈리기 쉬울 것 같다) greedy기법을 이용하여 이를 분석하면
complex와 houses가 스택안에 들어오면 이를 houses는 명사로, complex는 houses를 설명하는 형용사로 간주할 가능성이 크다.

이렇게 맨 초반부터 분석 실수를 하게되면 다시 되돌아갈 수 없으므로 전체 문장 분석도 실패하게 될 것이다.
이 단점을 보완하고자 빔 탐색(Beam Search)이라는 전략을 사용한다.
빔탐색
각 단계에서 가장 가능성 있는 예측을 탐욕스럽게 선택하는 대신, 첫 k개의 동작과 이와 연관된 확률의 시퀸스에 대한 가장 가능성있는 가설의 빔(고정 빔 크기 b까지)을 유지하는 것이다
빔 탐색은 크게 확장(expansion)과 가지치기(pruning)라는 두 단계로 나눌 수 있다.
확장(expansion)
: 각 가설을 SyntaxNet의 가능한 입력으로 고려하고,
이 전체 동작의 공간에 대한 하나의 "확률분포"를 생성한다고 가정하자.
첫번째 k+1 동작들의 시퀸스에 대해 b*(동작의 공간) 개의 가능한 가설 각각에 대한 확률을 계산한다
가지치기(pruning)
b*(동작의 공간)개의 전체 선택중 가장 확률이 높은 b개의 가설만을 유지한다.
문장에서 나중에 더 올바르다고 밝혀질 가능성이 낮은 가설들을 초기에 고려해서 과거의 잘못된예측을 바로잡을 수 있게 한다.
다음 그림은 빔크기가 2인 빔 탐색의 결과로, 3개의 가능성중에 가장 가능성이 높은 2개를 유지한 것을 볼 수 있다

실제 답에 가까운 것은 left arc->right arc 임을 확인할 수 있다.
만약 이를 빔이 아닌 greedy방법으로 했다면 첫번째 선택에서 shift를 고른 시점부터 정답에 가까워질 수 없게된다.
문장 끝에 도달할 때 까지 or 올바른 동작들의 순서가 더는 빔에 포함되어 있지 않을 때 까지 고정된 빔의 크기로 탐색한 결과

다른 가설들과 관련된 점수를 최대화해 빔에서 가능한 높은 ' 황금표준'동작 시퀀스(답?)를 밀어 넣으려고 하는 손실 함수를 구성함
(파란색으로 표시해 둔 것이 황금 표준 동작 시퀀스)
전역 정규화(global noramlization)
위와같은 빔 탐색의 개념을 신경망 학습 과정에 적용하려고 시도한다.
전역 정규화(global normalization)과정은 실제로 지역 정규화보다 강력한 이론적 보장과 명확한 성능 향상 둘 다를 제공한다.
지역(local)정규화 vs 전역(global)정규화
| 지역 정규화 | 전역 정규화 |
| 주어진 구성에서 최선의 동작을 선택 | |
| 소프트 맥스 층을 사용해 정규화된 하나의 점수를 출력 지금 까지 수행된동작들을 제공해 모든 가능한 동작에 대한 확률분포 제작 |
동작당 확률 분포를 생성하기위해 하나의 가설 동작 시퀀스에 대한 모든 점수를 합산하여 소프트맥스층을 적용 |
| 손실 함수는 확률분포를 이상적 출력에 맞추려고 시도 | 이론적으로 교차 엔트로피 손실 함수 사용 가능 하지만, 가능한 가설 시퀀스의 수가 다루기 어려울 정도로 매우 많음 |
7.6 상태 기반(Stateful) 딥러닝 모델 사례
지금까지 전방향 신경망을 시퀀스 분석에 적용하기 위한 몇 가지 방법을 살펴봤지만, 아직 시퀀스 분석에 대한 elegant한 방법을 찾지 못했다.
품사 태거 예제 에서는 장기 의존성을 무시할 수 있따는 가정을 했고
빔 탐색과 전역 정규화의 개념을 도입하여 이 가정에 대한 몇가지 한계점을 극복 할 수 있었지만,
여전히 문제 공간은 입력 시퀀스의 요소들과 출력 시퀀스 요소사이가 일대일로 mapping된다는 것에 대한 제약을 받게된다.
예를 들어, 의존 구문 분석 모델에서 조차 구문 분석 트리와 아크-표준 동작들을 구성하는 동안 입력 구성들의 시컨스 간의 일대일 대응 문제를 재구성 해야했다
때때로 이 작업은 입력과 시퀀스 간에 일대일 대응을 찾는 것보다 훨씬 복잡하다.
ex) 전체 입력 시퀀스를 한 번에 사용할 수 있는 모델을 개발 ,
전체 입력의 감정이 긍정인지 부정인지 판단,
복잡한 입력을 받아들인 후 입력을 설명하는 한 문장을 한 번에 생성하는 알고리즘,
문장을 한 언어에서 다른 언어로 번역,
이 모든 예시를 보면 입력과 출력 토큰 사이에 명확한 대응이 없다.
*일대일 구성 문제에 대해서는 나중에...

모델이 입력 시퀀스를 읽는 동안 어떤 종류의 메모리를 유지해야하고,
입력을 읽는 동안 모델은 관찰하는 정보를 고려해 이 메모리 뱅크를 수정할 수 있어야 한다.
입력 시퀀스가 끝날 때까지 내부 메모리는 원래 입력의 주요 정보(의미를 나타내는 하나의 생각)을 포함한다.
원본 시퀀스의 레이블을 생성하거나 적절한 출력 시퀀스(번역,설명,추상 요약 등등 위의 예의 출력같은 것들)을 생성하기 위해 이 Thought벡터를 사용한다
전방향 신경망들은 본질적으로 상태가 없다(stateless)
학습을 마친 후의 전방향 신경망은 정적인 구조이다. 메모리를 유지하거나 과거의 입력을 기반으로 처리하는 방법을 변경할 수 없다.
이 전략을 시행하기 위해서는 상태기반 딥러닝 모델을 창조해야한다. -> 순환신경망(RNN)
7.7
<참고자료>
06. 합성곱 신경망 - Convolutional Neural Networks
이번 포스팅은 핸즈온 머신러닝 교재, cs231n 강의를 가지고 공부한 것을 정리한 포스팅입니다. CNN에 대해 좀 더 간략하게 알고 싶으신 분들은 아래의 링크를 참고하면 됩니다. 간략한 설명 : 합성
excelsior-cjh.tistory.com
Long Short-Term Memory (LSTM)
이번 포스팅에서는 Long Short-Term Memory (LSTM)에 대하여 작성하고자 합니다. LSTM은 이전 포스팅에서 다룬 RNN의 발전된 형태입니다. RNN 구조의 큰 특징은 과거의 정보를 은닉층에 저장하는 것인데, Ben
yjjo.tistory.com
https://www.youtube.com/watch?v=PahF2hZM6cs
blog.ilkyu.kr/entry/언어-모델링-ngram
[언어 모델링] n-gram
자연어 처리에서 확률의 중요성 우리가 자연어로 만들어내는 문장들은 정규화되지 않고 무한하며 복잡한 문법을 따르기 때문에 컴퓨터가 처리하기 어렵습니다. 하지만 효과적인 언어 모델링��
blog.ilkyu.kr
www.slideshare.net/ssuser760eb4/dependency-parser
Dependency Parser, 의존 구조 분석기
자연어 처리는 형태소 분석, 구문 분석, 의미 분석, 화용 분석의 단계로 진행된다. 본 자료에서는 구문 분석 중 구문 태깅 이후 의존 구조 분석에 대한 이론과 학습, 개발 결과를 정리했다. 이찬��
www.slideshare.net
https://www.youtube.com/watch?v=f5-hTA9hA3s
https://www.youtube.com/watch?v=pQ9Y9ZagZBk
'ML' 카테고리의 다른 글
| [딥러닝의 정석]05. 합성곱 신경망-2 (0) | 2020.08.03 |
|---|---|
| [딥러닝의 정석] 05. 합성곱 신경망-1 (0) | 2020.08.02 |
| [딥러닝의 정석] 04. 경사 하강법을 넘어서 (0) | 2020.07.27 |
| [딥러닝의 정석]03. 텐서플로로 신경망 구현하기-2 (0) | 2020.07.21 |
| [딥러닝의 정석]03. 텐서플로로 신경망 구현하기 (0) | 2020.07.18 |



