5.15 요약
예시 ) 이미지를 분석하는 신경망
합성곱의 개념 -> 자연이미지 처리에 용이
파이프라인 / 배치 정규화
텐서플로로 구현 / 시각화 / 합성곱 신경망 응용
5.1 인간 시각에서의 뉴런
인간의 시각 -> 매우 진보
- 매우 짧은 시간 안에 생각 없이 물체를 인식
- 물체를 명명 , 깊이 인지, 윤곽선 구분, 배경으로 부터 물체를 구분
- 데이터의 보셀(voxel : 3차원 공간에서 한 점을 정의하는 그래픽 정보의 단위 )을 수용 -> 선 과 곡선의 기본 요소로 변환
*Receptive fields and functional architecture of monkey striate cortex" - Huble ,DavidH. , Torsten N.Wiesel
일단 인간의 시신경에 대해 조금 알아보았다.
시각이라는 감각의 근본은 "뉴런"이다.
특화된 뉴런은 인간의 눈에서 빛 정보를 포착하는 역할을 담당하는데
이 빛 정보가 전처리 되어 뇌의 시각 피질로 전달되고, 분석이 되어 물체를 파악할 수 있다.

망막 안쪽으로 빛이 들어오게 되면 망막의 바깥쪽 까지 전달되어 광세포(Rod/Cone)가 먼저 인지 한 후
앞쪽으로 전달하면서 시각화를 진행한다

인간의 망막은 사실 투명한 10계층 구조로 이루어져있다. (투명하기 때문에 빛이 들어와 가장 끝부분인 Rod/Cone)
가장 바깥쪽인 1계층에 존재하는 광(수용기)세포(phtoreceptor cell)인 Rod(막대세포)와 Cone(원뿔세포) 은 빛 정보를 포착한다.
광 세포는 전기, 화학적 신호를 만들어 양극세포로, 양극세포는 신경절 세포로 전달하게 되는데 신경절 세포의 축삭이 시신경 섬유이다.
이는 시신경 유두로 모아져 시신경을 따라 대뇌로 이동한다
"Rods and Cones" - Cohen, Adoph I.
자세한 것은 여기서 좀 더 참고 -> 망막의 10계층 : eyeamfinethankyou.com/378
이러한 모든 기능을 뉴런 단독으로 책임진다.
이제 인간의 시각에 대한 이해를 바탕으로 이미지 문제에 대한 효과적인 딥러닝 모델을 구축해보자
그 전에 이미지 분석에 대한 전통적인 접근법들과 실패 요인에 대해 알아보도록 한다.
5.2 특징 선택(Feature Selection)의 단점
임의로 주어진 이미지에서 사람의 얼굴이 있는지를 판별하는 일을 한다고 하자.
사람에겐 아주 쉽겠지만 기계에게는 그렇지 않다.
우리가 1단원부터 살펴본 전통적 머신러닝 알고리즘에 원시 픽셀값을 input값으로 주고 적절하게 학습 하는가 지켜보면,
신호대비 노이즈 비율(signal to noise ratio, SNR)이 너무 낮아 제대로 작동하지 않는다.
신호대비 노이즈 비율(SNR)
사진의 화질(오디오의 음질 등등)을 표현하는 용어로서 , 주어진 시점에서 원하는 신호의 크기와 잡음 신호 크기의 비율이다.
수치가 클수록 화질/음질이 좋다는 의미.

먼저 이미지 분석에 대한 전통적 접근중 하나였던 Paul Viloa-Michael Jones의 "Rapid Object Detection using a Boosted Cascade of Simple Features" 에 제시된 방법을 살펴보도록 한다.
위의 방법의 실패에 대한 절충안으로, 전통적 프로그래밍 방식(인간이 모든 로직을 지정)과 순수 머신러닝 접근 방식 사이에 균형점을 잡았다.
인간이 얼굴을 인식(얼굴을 주변 배경과 분류하고 결정 시) 중요하다고 믿는 특징들을 선택한 다음, 동일한 학습문제에 대해 "더 저차원의 표현"을 생산해낸다.
그러면 머신러닝 알고리즘은 classification을 위해 이 새로운 특징 벡터들을 사용한다.
특정 추출 프로세스가 신호대비노이즈 비율을 개선하므로, 그 결과는 당시 최고 기술 수준보다 효과적이었다.
비올라와 존스(인간)은 얼굴에 그들이 활용할 수 있는 밝고 어두운 부분의 어떤 패턴이 있다는 사실을 알아냈고,
예를 들어 눈 영역과 위쪽 뺨 사이에 빛의 강도 차이가 존재하며 (눈은 깊게 들어가있어 어둡고 위쪽 뺨은 밝다)
, 콧등은 양쪽 눈 사이와 차이가 있다
(이런 사실은 사실 그냥 보면 모르겠고 이목구비가 매우 뚜렷한 외국인을 보면 바로 무슨뜻인지 알 수 있다..ㄱ-)

그 패턴들을 특징으로 추출하여 머신러닝에게 제공했다 -> 위의 2,3번째 사진에서의 네모들을 특징 검출기라고한다
이러한 특징 하나하나는 얼굴을 인식하는데 효과적이지 않지만 , 수백 수천개의 특징을 동시에 활용하면 효과가 극적으로 증가한다.
이 알고리즘은 결과적으로 91.4%의 검출률을 달성했다.
하지만 이러한 특징추출 방법에는 근본적인 한계가 있다.
다음 그림들과 같이 빛의 강도가 인식되지 않는 경우들은 실패할 가능성이 높다

이를 통해 알고리즘이 얼굴을 "본다"는 의미가 무엇인지 실제로 배우지 못했다는 것을 알 수 있다.
인간의 뇌가 사진에 포함되어있는 사진을 "본다"라는 것은 인간의 얼굴의 빛의 강도 차이를 암기하여 판단하는 것이 아니라,
윤곽선, 안면 특징,상대적 위치, 색을 포함한 방대한 양의 시각적 단서를 사용한다.
위의 만화 캐릭터를 볼 때, 우리는 얼굴에 빛의 강도의 차이가 없음에도( 시각적 단서중 몇몇에 약간의 불일치가 있더라도 ) 시각 피질은 여전히 안정적으로 이것이 인간의 얼굴임을 알 수 있다.
컴퓨터에게 보는 것을 가르치기 위해서 전통적 머신러닝 기법을 사용하려면 결정을 내리기 위한 더 많은 특징을 프로그램에 제공해야 하는데, 이 특징들의 유용성을 토론하는 대에만 수년이 걸린다.
또한 인식의 문제가 점점 복잡해지면서 그에 대해 대처하기 어려워졌다.
그러던 중 컴퓨터 비전 올림픽인 ImageNet Challenge에서
2012년 토론토대학교 제프리 힌튼 연구실의 알렉스가 처음으로 "합성곱 신경망(Convolutional Neural Network,CNN)"이라는 딥러닝 구조를 개척하므로서 오차율을 10%이상 감소시켰다.
알렉스넷은 컴퓨터 비전* 영역에 혼자서 딥러닝을 넣었고, 이 분야에서 완전히 혁명이었다.
*컴퓨터 비전 : 기계의 시각에 해당하는 부분을 연구하는 컴퓨터 과학의 최신 연구분야 중 하나
공학적 관점에서는 인간의 시각이라고 할 수 있는 몇가지 일을 수행하는 자율적인 시스템을 만드는 것을 목표로 함
과학적 관점에서는 이미지에서 정보를 추출하는 인공 시스템 관련 이론에 관함
5.3 크기 조정 없는 기본 심층 신경망(Vanilla Deep Nueral Network)
컴퓨터 비전에서 딥러닝을 적용하는 근본적 목표는 제한적인 특징 선택 과정을 제거하기 위함이다.
신경망의 각 층은 입력받은 데이터를 표현하는 특징들을 학습하고 만들어가는 책임을 가진다.
위와 같은 이론(?)을 지키면서 가장 단순하게 접근한 방법으로는 3단원에서 설계한 기본 심층 신경망(Vanilla Deep Nueral Network)을 이용하는 것이다.
3장에서 설계한 신경망을 그림으로 다시 살펴보면

28*28의 픽셀 흑백인 MNIST 이미지를 이용했으며, 완전연결을 사용했으므로, 3차원의 그림이 1차원으로 평평(flat)데이터로 펼쳐 784개의 1차원 데이터로 바꾼후 입력층으로 들어간다.
(총 (28*28=)784개의 입력가중치가 있다.)

기본 신경망을 이용해서도 이를 아주 잘 수행해 냄을보였지만,
만약 이미지가 200*200픽셀의 흑백이미지 였다면 (200*200) 40000개의 입력가중치를 가지게 될 것이며,
또한 흑백이 아니게 되면, 200*200*3(RGB) = 120000개의 가중치를 가지게 될 것이다.
그리고 이것이 다층에 걸쳐 많은 수의 뉴런을 가지게 되면 파라미터들이 매우 많아질 것이다.
보다시피 완전연결성은 낭비이며 과적합 가능성 또한 높아진다.
합성곱 신경망(CNN)은 인간이 이미지를 분석한다는 사실을 이용했다. (-> 다음 절 에서 간단하게 알아봄)
파라미터수를 줄이기 위하여, 위의 방법과 같이 3차원이던 이미지를 1차원으로 변형해 사용하는 것이 아니라
3차원 이미지를 그대로 사용하고, 합성 신경망의 layer층들의 뉴런들을 3차원으로, 너비 높이 깊이를 가지도록 정렬했다.

즉, 3차원 이미지를 그대로 input으로 사용하고, 층들도 3차원으로 배치하여(layer가 3차원의 뉴런 배치를 가짐), output또한 3차원으로 출력하여 다음 계층으로 전달된다
이렇게 되면 층이 작고 지역적인 영역이 되므로 완전연결 뉴런들의 낭비를 피할 수 있다.
즉, 기본 심층 신경망(Vanila deep neural network)은 이미지를 1차원으로 평평하게 만들어 784개의 1차원뉴런으로 받는다

따라서 심층 신경망의 구조는 다음과 같은 형태가 된다.
합성곱 신경망은 3차원의 이미지(28*28*1)를 받아 그대로 사용하므로 뉴런또한 3차원으로 배치되며,

각 층은 다음과 같이 3차원으로 표현된다

5.4 필터(filter)와 특징 맵(feature map)
합성곱층의 근본 원리 설명을 위해 인간의 이미지 분석에 대해 알아보자
"Receptive fileds of single neruones in the cat's striate cortex" - Hubel, David H., Torsten N. Wiesel
인간의 두뇌가 원시 시각 정보를 종합해 주변의 환경을 이해하는 법에 대한 가장 영향력있는 연구이다.
이들은 고양이의 뇌의 시각피질에 전극을 삽입한 후, 흑백 TV화면에서 기울어진 흰색 바(bar)를 생성하여 움직이면서
흰색 바의 모양 방향 등등에 따라 시각피질의 반응을 살펴보기 위하여,
고양이의 시각피질에 자극을 주어 전극에서 나오는 신호를 증폭해서 오디오로 들어보았다.
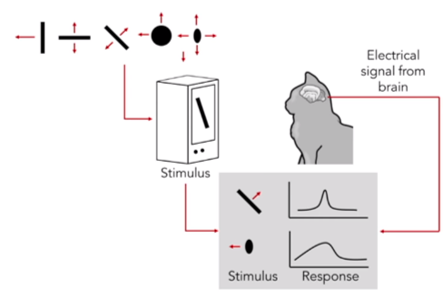
뉴런에서 뉴런이 활성화될 조건을 만족시켜 신경 세포내 생화학적 전기적 점화가 발생하게 될때, 그 부위 근처에 (고양이의 시각피질에 삽입해 둔)전극이 위치한다면 노이즈가 발생한다.
노이즈가 발생하는 위치에 표시를 해본 결과
어떤 뉴런들은 수직선이 있을때만, 어떤 뉴런은 수평, 또 어떤 뉴런은 특정 각도로 기울어진 사선에만 반응한다는 것을 발견했다.
이 결과에 의하면
고양이의 시각 피질은 흑백 이미지에서 밝기가 변하는 사선이나 배경색과 대조되어 움직이는 사선 등, 수직, 수평, 사선의 edge를 탐색할 수 있으며,
edge의 크기, 기울어진 각도, edge의 움직이는 방향을 알아내는 세 종류의 뉴런들로 구성되어 있다는 점을 알아냈다.
| 세포의 종류 | 알아 낼 수 있는 정보 |
| Simple | 방향, 위치 |
| Complex | 방향, 위치, 움직임 |
| Hypercomplex | 방향, 위치, 움직임, 길이 |
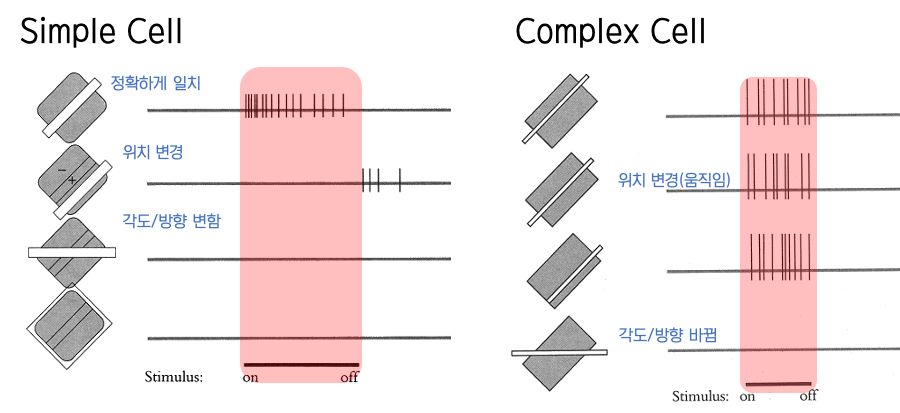
simple cell은 특정 모양이 특정 위치(특정 모양과 특정 위치를 가진 특징 검출기와 동일하면 활성화)에 존재할 때만 활성화 된다. //엄격
만약 위의 뉴런이 활성화 되었다면, 지금 보고있는 물체가 첫번째 줄의 모양과 위치를 가진 물체라는 것을 알아낼 것입니다.
이것이 활성화 된 상태에서 complex cell의 (각도와 모양이 동일한 것의) 위치가 변경되는 부분의 cell이 활성화 되었다면, // simple cell보다는 엄격하지 않음
해당 모양과 위치를 가진 물체(simple cell)가 움직이고 있다고 인지 할 수 있게된다.
위와 같이 이 세 종류의 뉴런(다른 동물들은 어쩌면 그 이상의)이 각자 맡은 부분을 탐색해 그 종합적인 정보를 이용해 물체와 그 물체의 상태를 인식하게 되는 것 입니다.
정확히 이렇다고 말할 수는 없지만 대체적으로 이런 방식이다.
물체의 여러 정보를 판단하는 뉴런들이 종류별로 존재(기울기 판단뉴런, 길이 판단 뉴런, 움직임 판단 뉴런 등등)하고
예를들어 물체의 기울기를 판단하는 종류의 뉴런이라고 하면, 어떤 뉴런이 활성화 되었는지에 따라 해당 물체의 edge가 어느정도 기울기인지 알아낼 수 있게되며,

시각피질은 여러층으로 구조화 되어있어 각 층별로 담당하는 일이 다르다.
1,2계층은 전체적인 이미지, 3계층은 주변형태, 4계층은 형태와 색, 5계층은 운동감지 등등

이전 층에서 감지된 특징들을 그 위에 쌓아 올리며 어떤 이미지인지 인식할 수 있게 된다.
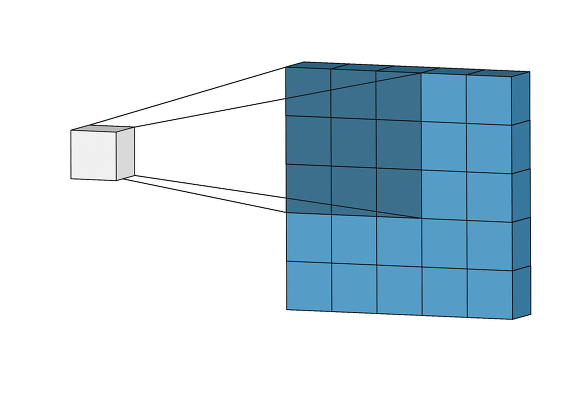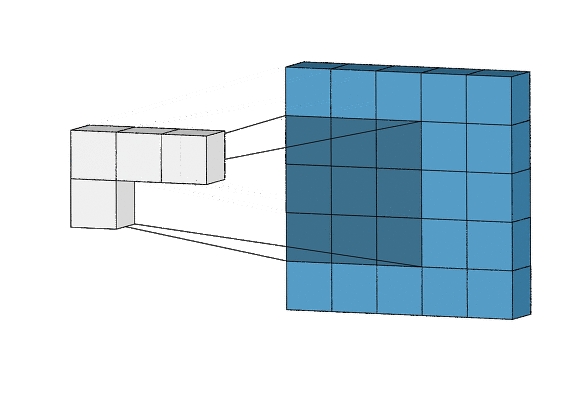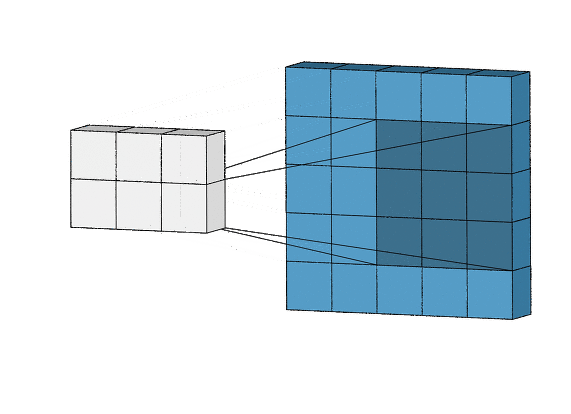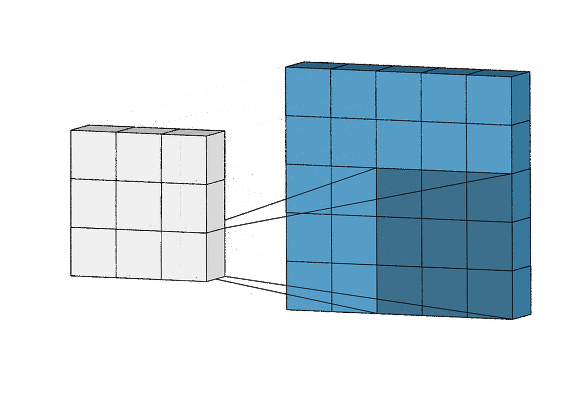
또한, 시각 피질 층 안에서 동일한 특징 검출기가 이미지의 모든 부분에서 특징을 검출하기 위해 전체 영역에 걸쳐 복제된다
예를 들어 다음과 같은 특징 검출기( 이런특징이 있으면 활성화 되는 뉴런)이 있다고 하면

다음과 같은 그림에서 해당 검출기와 같은 특징이 있는 곳을 검출해 내기 위하여 전체 영역에 대해 스캔한다

현재는 하나의 검출기에 대해서만 스캔하였기 때문에 edge로 그림을 판별하기 어렵지만, 매우 많은 검출기에 대하여 진행한다면
edge를 거의 정확하게 알아낼 수 있을 것이다.
이 아이디어들은 합성곱 신경망 설계에 큰 영향을 미쳤다.
이렇게 해서 이미지를 인식하는 신경망에 등장한 첫번째 개념이 필터(filter)이다.
필터는 본질적으로 위의 그림에서 나온 특징 검출기와 같은데, 결국은 Viloa와 Jones의 연구가 실제로 매우 근접했음을 알 수 있다.
어떻게 작동하는지 알아보자.

다음과 같은 이미지가 있다고 할때, 여기서 수직선/수평선을 각각 검출하는 2개의 특징검출기를 사용한다고 하자
전체 이미지를 스캔하면서 단계마다 그림과 필터가 동일한지 확인하고, 행렬에 답을 기록한다.
행렬상에 일치하면 검은색으로 일치하지 않으면 흰색으로 남겨둔다

다음의 결과 행렬이 바로 특징 맵 (feature map)이며, 원본 이미지에서 찾는 특징을 어디에서 발견했는지 표시한다.
이 연산을 바로 합성곱(convolution)이라고 한다.
컨볼류션(Convilution)이라는 단어가 익숙치 않을 수 있는데 revolution 이라는 단어를 비교해보자.
아주 알기 쉽게 서부영화에서 흔히 보는 6 발짜리 리볼버(Revolver)권총을 생각하면 된다.
volution 은 돌린다는 의미며 revolve 는 하나의 중심 축을 중심으로 돌린 다는 뜻임에 반해 Convolve 는 큰 사각형 안에서 작은 사각형을 위에서부터 양쪽 모서릴 사이를 왔다 갔다 하는 TV 주사선 방식으로 스캔하면서 움직인다는 의미이다.
steemit.com/kr/@codingart/4-4-nn-neural-network-deep-learning-cnn
하나의 필터를 취하고 입력 이미지의 전체 영역에 걸쳐 이 필터를 곱한다.
전방향 신경망의 뉴런층들은 원본 이미지 또는 특징맵을 표현한다
필터는 입력 전체를 넘어 복제되는 연결의 조합을 나타낸다. ( 아래 그림에 강조된것이 조합 1개)
같은 색의 연결들은 항상 동일한 가중치를 갖게 제한된다

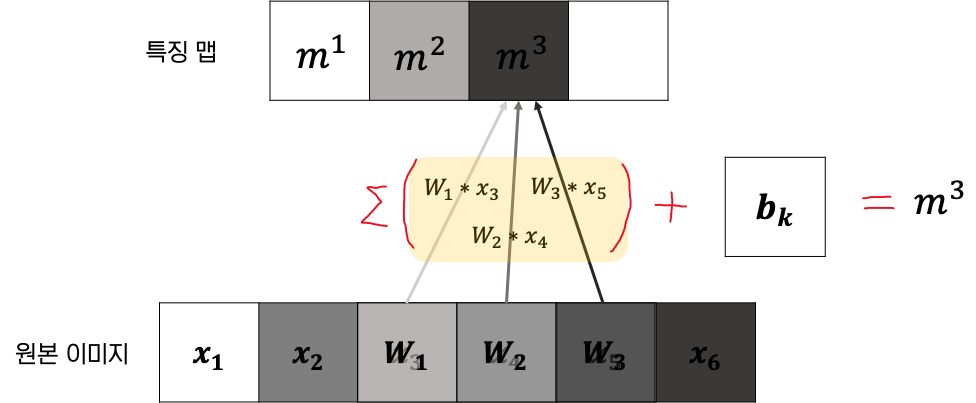
m층의 k번째 특징맵을 m^k라고 하고, 이것의 가중치 W의 값들로 해당 필터를 나타낸다.
그 다음 특징맵의 뉴런들의 바이어스를 b^k라고 가지면,(바이어스는 특징맵의 모든 뉴런에 대해 동일하게 유지)
다음과 같이 특징맵을 수학적으로 표현할 수 있다.

여기까지가 책에 나온 설명인데, 이 그림을 내가 나름대로 해석해 본 걸 쉽게 그림으로 설명하자면 //쉬운 설명을 위해 함수 f는 제외함
아래쪽의 6개의 뉴런층은 원본이미지 또는 m-1 의 특징맵이다 (여기서는 원본이미지라고 하였다)
입력값이니 x로 표현하기로 한다.
필터는 1*3의 크기로 필터로, 3개의 가중치를 가진다. -> 이것이 바로 vanila심층 신경망 보다 훨씬 파라미터를 줄일 수 있는 비결(?)
편향은 output으로 생성될 특징맵의 모든 뉴런에 대해 동일하므로 1*1로 설정

이제 필터를 각각 움직여 위의 수식대로 계산하며 특징맵을 생성해 낸다
< STEP 1 >

< STEP 2 >

< STEP 3 >
< STEP 4 >

output(출력층)으로 1*3크기의 동일한 필터에 의한 1*4의 특징맵이 생성되었다.
특징맵에서 뉴런은 뉴런의 활성화 정도에 기여하는 필터가 이전 층(원본 이미지)의 해당위치에서 적절한 특징(필터와 유사)을 탐지하면 활성화(더 진한색으로 표현)된다.
위의 문장을 더 잘 설명하기 위하여 특징맵의 색을 수정해서 더 직관적으로 표현했다.

어떤 느낌인지 감이 왔길 바란다
이 설명은 간단하지만, 합성곱 신경망에 사용될 때 처럼 필터들을 완벽하게 설명하지는 못한다.
특히, 필터는 단일 특징 맵에서만 작동하지 않는다.
필터는 특정 층에서 생성되어 전체 특징맵에서 작동한다.
예를 들어 어떤 이미지에서 사람의 얼굴을 인식해 내는 합성곱 신경망을 만들면,
각각 눈을 인식하는 필터, 입을 인식하는 필터, 코를 인식하는 필터를 이용해 계층별로 적용했다고 하자
그렇다면 3개의 특징맵이 추출될 것이다

얼굴의 존재를 결정하기 위해 여러 특징 맵에 걸쳐 단서를 결합해야 한다는 것이다.
이것은 색상 입력 이미지에 대해서도 똑같이 필요한데, 이 이미지들은 RGB값으로 표현된 픽셀들을 가진다.
이미지들은 RGB값으로 표현된 픽셀들을 가지므로, 입력 볼륨에서 3조각이 필요하다
결과적으로 특징맵은 단지 영역이 아닌 입력 볼륨(입력이미지)에 걸쳐서 작동할 수 있어야 한다.

(한 부분은 뉴런들의 볼륨이 있는 층에 대한) 특징맵에서 "하나의 뉴런"을 생성하기 위해 필터와 곱해진다
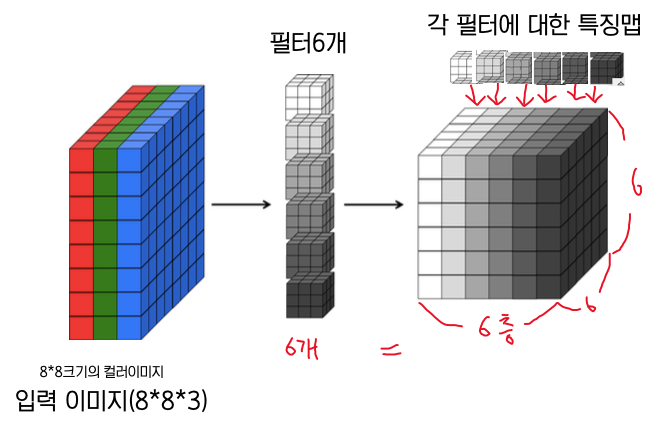
다음 그림은 필터를 6개 사용해서 출력 특징맵의 볼륨을 6으로 만든 것이다. (출력 볼륨의 깊이 = 해당 층의 필터 수)
하나의 합성곱층은 한 값의 볼륨을 또 다른 값의 볼륨으로 변환한다(필터의 깊이 = 입력 볼륨의 깊이)
합성곱층의 출력 볼륨의 깊이는 해당 층의 필터수와 같다, 이것은 각 필터가 그 자신의 조각을 각각 생성하기 때문이다
5.5 합성곱층 정리
합성곱층의 입력 볼륨(입력 이미지)
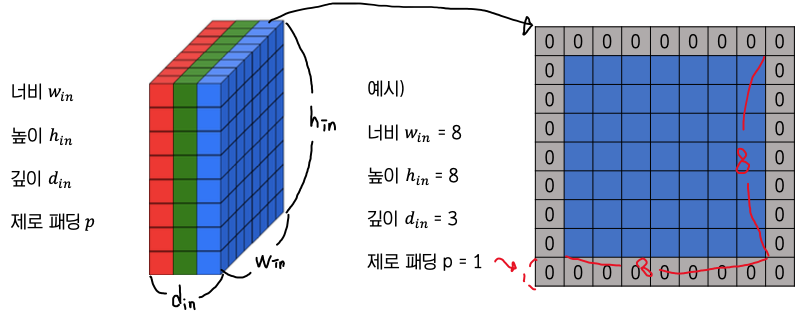
합성곱층의 입력 볼륨(입력 이미지)에 대해서 용어는 다음과 같으며
depth는 채널이라고도 함
제로 패딩은 데이터 주변에 0을 채워 여백을 주는 것이다 ( 1로 채우는 패딩도 존재함)
왜 이런 일을 하냐면, 아래그림을 보자.
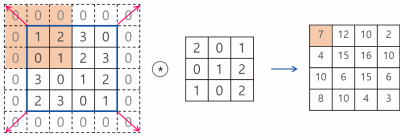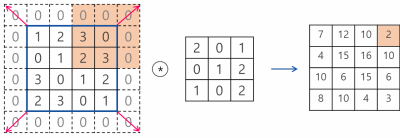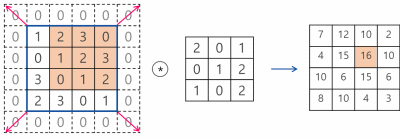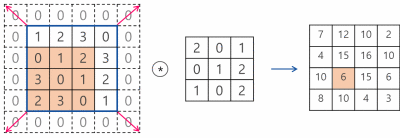
입력볼륨이(5*5*1)이고 필터가 (3*3*1) 이라고 하자, 필터를 한칸씩 이동(아래서 나오겠지만 이동을 얼마나 하느냐를 stride라고한다 / s =1 )하면서 전체 입력볼륨을 스캔해서 출력볼륨(특징맵)을 만들었다.
특징맵의 크기는 (stride가 1이라면) 입력볼륨의 (w-2, h-2, 1)이 될 수 밖에 없다.
하지만 실제 코드를 작성할 때는 입력볼륨과 출력볼륨의 크기를 동일하게 하는 것이 좋으므로 이를 위해
padding크기를 1로 부여하고 패딩을 부여한 입력볼륨(7*7*1)에 대하여 필터를 적용하면, 실제 입력 볼륨의 크기인 (5*5*1)로 출력 볼륨이 나오게된다.
필터(filter)
이 볼륨은 총 k개의 필터로 처리되는데, 이것은 합성곱 신경망의 가중치와의 연결들을 나타낸다.
이 필터들은 다음의 몇가지 하이퍼 파라미터를 가진다.
- 공간 범위(spatial extent) e : 필터의 높이/너비 (필터는 주로 정사각형이므로 높이와 너비가 같음)
- 보폭(stride) s : 입력 볼륨에서의 필터의 연속적인 적용 사이의 거리 , 필터를 몇칸 이동할 것인가
- 바이어스(bias) b : 필터 값 처럼 학습된 하나의 파라미터
출력 볼륨
결과적으로 다음과 같은 특성을 갖춘 출력 볼륨이 생성된다
함수 f : 최종값을 결정하기 위한 출력 보륨에서 각 뉴런의 입력 로짓에 적용

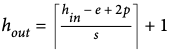

예를 들면, 다음 그림은

+> 함수 f(z) = z
을 가진다고 할 수 있다.
l<= m <= k 출력 볼륨의 m번째 깊이조각(depth slice)는 입력 볼륨과 바이어스 b(m)이 얽힌 m번째 필터의 합을 f에 넣어 계산한 값이 된다
또한, 이것은 필터당 개의 d(in) ^ e^2 파라미터가 있다는 뜻이며,
전체적으로 한층에 k * d(in) * e^2 개의 파라미터와 k개의 바이어스가 있다는 의미이다.
(바이어스는 특징맵의 모든 뉴런에 대해 동일하게 유지)
p = 1, s = 2 , f(z) = z를 사용하여 계산하면 다음과 같다

위으 그림에서는 필터당 d(in) ^ e^2 = 3*3*3 = 27개의 파라미터가 있고,
전체적으로는 한층에 k * d(in) * e^2 = 필터 수 * 필터하나의 파라미터 수 = 2 * 27 = 54 개의 파라미터가 존재한다고 할 수 있다.
여러가지 특성들
일반적으로 필터의 크기를 작게 유지하는 것이 현명하다. (3*3 / 5*5 정도)
큰 크기들(7*7)은 첫번째 합성곱층에서만 사용된다.
더 작은 필터를 갖는 것은 더 적은 수의 파라미터를 발생시키면서 더 세부적으로 스캔하므로 높은 표현력을 달성할 수 있다.
토한 특징맵에서 모든 유용한 정도를 잡아내기위해 s = 1을 주로 사용하며,
제로패딩을 이용하여 출력볼륨의 높이와 너비를 입력볼륨의 높이및 너비와 동일하게 유지한다
연산을 수행할 때는 입력의 채널수와 필터의 채널수가 같아야한다.
conv2d
텐서플로에서는 입력볼륨들의 미니배치에서 합성곱을 쉽게 수행하도록 편리한 연산을 제공한다.
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=True, name=None)입력은 N*h*w*d인 4차 텐서이며 (N은 미니배치에서의 예제의 수)
필터 인자는 합성곱을 적용한 모든 필터를 나타내는 4차원 텐서이며 크기는 e*e*d*k이다.
이 연산으로 나온 결과 텐서는 입력과 동일한 구조를 가진다.
padding인수를 SAME으로 설정하면, 제로패딩을 선택하여 자동으로 높이와 너비를 보존해준다. (입력/출력의 h,w크기가 같도록)
5.6 최대 풀링 (max pooling)
특징맵의 차원을 줄이고 특징들을 뚜렷하게 나타내기 위하여 합성곱층 당므에 최대 풀링 층을 삽입한다.
최대 풀링(max pooling)은 각 특징 맵을 균등한 크기의 타일로 분해하는 것이다.
각 타일에 대해 셀을 만들고 타일의 최대값을 계산한 후 최대값을 요약한 특징맵의 셀로 전파한다.

풀링층은 2개의 파라미터를 가진다
공간범위 e
보폭 s
이를 적용하면 결과값은 다음과 같다

최대 풀링은 지역적으로 불변한다.
입력이 조금씩 밀리거나 공간범위가 커져도 최대 풀링층의 출력은 거의 동일하게 유지된다 -> 최대값은 보통 가장 크니까
정확히 어디에 위치해있는지 보다 몇가지 특성이 존재하는지를 신경 쓴다면 매우 유용한 속성이다. -> 최대값이면 가장 영향력이 큰(?) 두드러지는 특성이므로, 최댓값을 뽑아내면 정확한 위치는 알 수 없지만 특성이 존재하는 지는 알 수 있음
하지만 공간범위가 너무 커지면 신경망의 중요한 정보 전달 능력이 손상될 수 있다. 따라서 풀링층의 공간범위는 보통 아주 작게 유지한다.
+ 추가 ) 부분 최대 풀링(fractional max pooling)
풀링을 위해 정수가 아닌 길이의 타일을 만드는데 의사 난수 생성기를 사용함
결론적으로 부분적 최대 풀링은 강력한 정형화기로써 작동하며, 합성곱 신경망에서 과적합을 방지하는데 도움이 됨
5.7 합성곱 신경망의 전체 구조
이제 실제로 사용되는 다양한 합성곱 신경망의 구조의 예에 대해 조금 살펴보도록 한다.

심층 신경망을 만들 때는 풀링의 수를 줄이고, 그. 대신 여러개의 합성곱 층을 세로로 쌓는 것이다
풀링층의 연산들은 본질적으로 차원이 줄어드므로 파괴적이다.
따라서 앞에 합성곱층을 넣는 것이 일반적으로 도움이 된다.
각 풀링층 앞에 여러 합성곱층을 쌓으면 더 풍부한 표현을 얻을 수 있다.
현실적으로 합성곱 신경망은 상당한 양의 메모리 공간을 차지할 수 있으며, GPU 메모리 용량 때문에 병목현상이 발생할 수 있다
많은 심층 신경망은 신경망에 전파해야하는 정보의 양을 줄이고자 첫번째 합성곱 층에서 보폭(s)과 공간범위(e)를 사용해 절충안을 만든다
<참고자료>
인간의 시신경
망막과 시신경, 시각 경로 알아보기~
우리가 어떠한 사물을 보게 되면, 사물에서 나오는 빛은 안구 내부로 들어오게 됩니다. 이때 빛은 각막(cornea)과 수정체(lens)에 의해서 굴절 되어 안구 내부에서 축소된 상(image)을 맺게 ��
eyeamfinethankyou.com
망막 10계층
망막의 10층 (망막의 구조, Retina 10 layer)
망막은 총 10개의 층으로 구성되어 있는 조직입니다. 안구의 중심에 가까운 곳을 안층, 내층이라고 하고, 맥락막과 공막에 가까운 곳을 바깥층, 외층이라고 표현합니다. 우선 그 10개의 층을 살펴
eyeamfinethankyou.com
[머신 러닝/딥 러닝] 인공신경망 (Artificial Neural Network, ANN)의 종류와 구조 및 개념
그림으로 보는 인공신경망의 종류 및 구조 그림 1은 다양한 인공신경망 (Artificial Neural Network, ANN)의 종류와 개념을 시각적으로 보여주며, 원본 그림은 The Asimov Institute에서 확인할 수 있다. 이 글��
untitledtblog.tistory.com
06. 합성곱 신경망 - Convolutional Neural Networks
이번 포스팅은 핸즈온 머신러닝 교재, cs231n 강의를 가지고 공부한 것을 정리한 포스팅입니다. CNN에 대해 좀 더 간략하게 알고 싶으신 분들은 아래의 링크를 참고하면 됩니다. 간략한 설명 : 합성
excelsior-cjh.tistory.com
m.post.naver.com/viewer/postView.nhn?volumeNo=24426232&memberNo=29566044
04. 모든 삶의 필수 요소인 시각은 어떻게 동작하는 것일까?
[BY 더굿북] 시각적 인지 사람은 눈으로 맛있는 음식, 아름다운 애인, 위험한 광경, 영어 문제를 보고...
m.post.naver.com
06. 합성곱 신경망 - Convolutional Neural Networks
이번 포스팅은 핸즈온 머신러닝 교재, cs231n 강의를 가지고 공부한 것을 정리한 포스팅입니다. CNN에 대해 좀 더 간략하게 알고 싶으신 분들은 아래의 링크를 참고하면 됩니다. 간략한 설명 : 합성
excelsior-cjh.tistory.com
'ML' 카테고리의 다른 글
| [딥러닝의 정석]07.시퀀스 분석을 위한 모델 (0) | 2020.08.03 |
|---|---|
| [딥러닝의 정석]05. 합성곱 신경망-2 (0) | 2020.08.03 |
| [딥러닝의 정석] 04. 경사 하강법을 넘어서 (0) | 2020.07.27 |
| [딥러닝의 정석]03. 텐서플로로 신경망 구현하기-2 (0) | 2020.07.21 |
| [딥러닝의 정석]03. 텐서플로로 신경망 구현하기 (0) | 2020.07.18 |



