무언가 프로젝트를 시작하기 전에 꼭 해야하는게 있다.
바로 기초 스터디..! 여기를 잘 하지 않고 일단 얼레벌레 넘어가서 시작부터 하면
언젠간은 꼬인 곳을 풀어내지 못해 다시 처음으로 돌아갈 확률이 높다.
YOLO는 뭔가.. 자료도 생각보다 적고, 영어로된 부분이 많고 darknet, darkflow... 뭔가 나눠져있는게 많기 때문에 일단 간단하게라도 알아봐야겠다.
기초 스터디를 할 때 가장 먼저 해야할 것은 바로 공식문서 읽기다...(대부분 영어)
먼저 YOLO darknet공식문서 부터 읽어본다.
직접 번역한거라 오류가 많을 수도 있으니 참고용으로만 읽어주시길 바랍니다.. 부끄러운 영어실력
What is YOLO?
YOLO v3 에 대한 공식문서 (가장최근) -> 일단 여기 기준으로 번역중
YOLO: Real-Time Object Detection
YOLO: Real-Time Object Detection You only look once (YOLO) is a state-of-the-art, real-time object detection system. On a Pascal Titan X it processes images at 30 FPS and has a mAP of 57.9% on COCO test-dev. Comparison to Other Detectors YOLOv3 is extremel
pjreddie.com
YOLOv2에 대한 공식문서
YOLO: Real-Time Object Detection
YOLO: Real-Time Object Detection You only look once (YOLO) is a state-of-the-art, real-time object detection system. On a Titan X it processes images at 40-90 FPS and has a mAP on VOC 2007 of 78.6% and a mAP of 48.1% on COCO test-dev. Model Train Test mAP
pjreddie.com
저는 Darkflow를 사용하는데 거기는 YOLOv2이므로... 일단 이것도 올렸습니다.
YOLO : Real-Time Object Detection (실시간 객체 탐지)
YOLO(You Only Look Once)는 현재 최고 수준의 실시간 객체 탐지 시스템입니다.
*COCO test-dev에 대해여 57.9%의 *mAP수준의 성능을 보이며, Pascal Titan X(GPU)를 이용했을 때 기준 30FPS의 속도로 이미지를 처리합니다.
그냥 수치상으로 YOLO가 얼마나 뛰어난지를 보여주는 것 입니다.
COCO(Common Objects in Context) test-dev란?
COCO는 매우 큰 규모의 객체 탐색, 분류, 세분화 등의 dataset인데, 성능 테스트용으로 많이 사용하는 dataset인 것 같다.. 정확히는 모르겠음

mAP란?
CNN모델은 평가할 때 mAP를 이용한다.
AP(Average Precision)를 주로 사용하는데, 높을 수록 전체적인(정확도, 검출율 등등) 알고리즘의 성능이 우수하다고 한다.
앞에 m이 붙은 것은 mean으로 클래스당 AP를 구한 후 모두 합하여 물체의 클래스로 나누어준 것이라고 한다.
자세한 것은 아래링크를 참고, 그냥 높을수록 알고리즘의 전체적 성능이 좋은 것이라고 생각하면 될듯.
mAP(Mean Average Precision) 정리
☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다. ☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습
ctkim.tistory.com
FPS?
초당 프레임, 1초당 몇개의 프레임을 처리하는지 이다.
30FPS는 1초당 30장의 프레임을 처리할 수 있는 것.
음.. 엄청나게 중요한 개념보다는 그냥 여튼 이만큼 YOLO가 좋다! 가 결론인 것 같아요
다른 Detectors들과의 비교
YOLOv3는 놀랍도록 빠르고 정확합니다. *.5 IOU YOLOv3의 mAP측정 결과 *Focal Loss와 같은 수준이었지만, 속도는 4배 이상이었습니다.
더욱이, 사용자가 "속도(speed)"와 "정확성(accuracy)"를 쉽게 교환(trade-off)할 수 있습니다. 단순하게 model의 size만 변경하면 되기 때문에, 학습을 다시 시킬 필요가 없습니다.
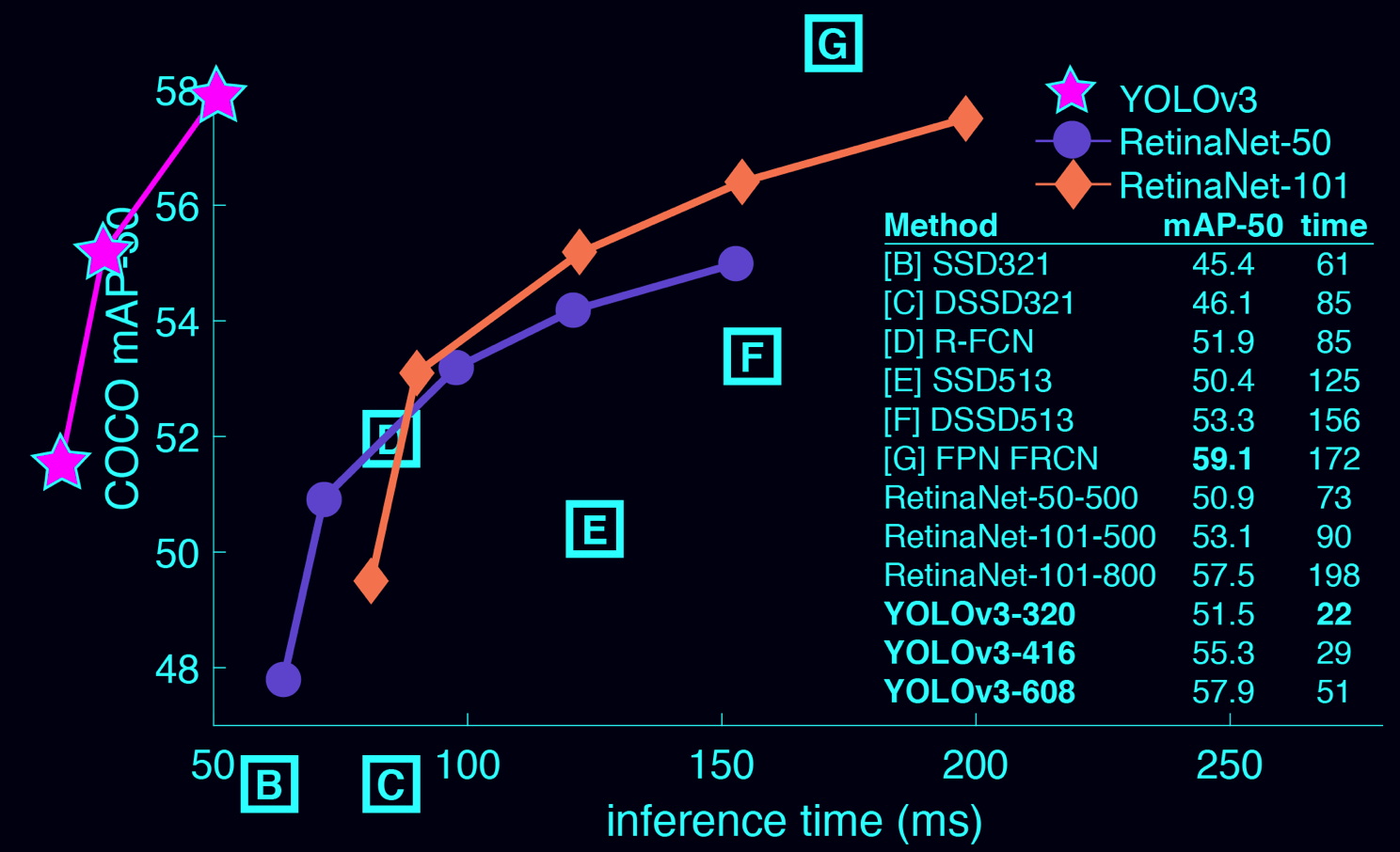
inference time : 하나의 frame에서 detection을 해내는 시간
그래프를 보시면 YOLOv3가 확실하게 시간이 더 적은것을 볼 수 있네요
*.5 IOU YOLOv3
일단 이게 무엇인지 알기 위해서는 IOU라는 개념에 대해서 알필요가 있습니다.
IOU
두 바운딩 박스가 겹치는 비율을 의미하는데, 만들어 낸 모델이 탐지한 결과와 실제 답을 비교했을 때 특정 IOU이상이 겹쳤을 때만 답이라고 분류하도록 합니다. 보통 0.5 (50%를) 주로 사용한다고 합니다.
즉 .5 IOU YOLOv3는 YOLOv3를 학습 시킬 때, 정답과 욜로 모델이 50%이상 겹칠 때 정답으로 판정하도록 테스트한 것 입니다.
자세한 내용은 아래 링크를 참고하시면 됩니다
Object Detection에서의 IoU, Precision, Recall 설명
물체 탐지(Object Detection)에서는 성능 평가 지표로 mAP와 recall이 사용된다. 한 논문에서 제안한 방법이 얼마나 효과적인지 이해하기 위해서는 이 평가 지표가 어떤 의미로 사용되었는지 정확히 알
ndb796.tistory.com
*Focal Loss
Focal loss는 RetinaNet이라는 곳에서 쓰인 감소함수(loss function)입니다.
YOLO가 아니니 자세히 설명하지 않겠습니다.
Focal loss
Focal loss 논문 Focal loss는 object detection의 한 종류인 retinanet에서 쓰인 loss function 입니다 다른 블로그에 가면 Focal loss에 대해 설명을 아주 자세하게 해놓은 곳이 많은데 간단하게 Focal loss를..
ufris.tistory.com
결론은 뭐 타 Detector인 FocalLoss와 성능은 유사하지만 속도는 4배나 빨라서 더 좋다! 뭐 이런 우월성을 객관적인 지표로 한번더 이야기하고 있습니다.
COCO Dataset에 대한 성능 표
차례대로,
모델명, 학습에 사용한 데이터, 테스트에 사용한 데이터, 알고리즘 완성도 지표, ?? , 속도, cfg, weights 를 보여줍니다.
실제로 사이트에 들어가서 cfg/weight를 클릭하면 다운받아서 테스트해볼 수도 있습니다.
-> Pre Trained Model 사용해보기에서 사용됩니다.
cfg와 weight가 무엇인지는 아래에서 한번더 설명할 기회가 있을 것입니다. (왜냐면 저도 자세히 몰라서 알아봐야함..)

어떻게 작동하는가?
이전의 detection 시스템은 classifier나 localizer가 detection의 기능을 할 수 있도록 다시 재구성한 것이었습니다.
이 방안은 모델에 다양한 location과 scale(크기)를 가진 이미지를 주어(apply), 이미지 내에서 높은 점수가 나오는 지역을 detection으로 판정했습니다.
하지만 우리는 완전히 다른 접근법을 사용했습니다. 우리는 하나의 신경망에(single neural network)에 전체 이미지(full image)를 줍니다.
이 신경망은 이미지를 지역(region)으로 나누고, 각 지역에 대해서 bounding box와 가능성/확률(probabailities)를 예측합니다.
이런 bounding box들은 예측된 확률(probabilties)에 의해 가중치가 부여됩니다.
우리의 모델은 classifier-based system에 비해 몇가지 장점을 가지고 있습니다.
우리 모델은 전체 이미지를 test time내에 보기 때문에, 이미지 내의 전체적인 상황/느낌(global context)을 이용하여 예측할 수 있습니다.
또한, 하나의 이미지에 대해 수천장이 요구되는 R-CNN과 같은 시스템과는 다르게 single network evalution을 이용해 예측해낼 수도 있습니다.
이 방법은 속도를 무지하게 빠르게 만듭니다. R-CNN보다 1000배 이상 빠르고, Fast R-CNN보다 100배 이상 빠릅니다.
우리의 논문을 보시면 full system에 대한 자세한 정보를 얻으 실 수 있습니다.
->위에서 언급한 논문은 이거에요
pjreddie.com/media/files/papers/YOLOv3.pdf
Version 2는 무엇이 달라졌는가?
YOLOv2는 몇가지 꼼수를 이용했습니다. 이것은 training을 효과적으로 할 수 있게 하고, perfomance를 증가시켜줍니다.
*Overfeat와 SSD(둘 다 Detector알고리즘 중 하나) 와 같이, *fully-convolutional model을 사용하였습니다. 하지만 우리는 여전히 *hard negative가 아닌, 전체 이미지(whole image)를 학습시킬 수 있습니다.
Faster R-CNN과 같이 우리는 width와 height(폭과 넓이)를 정확히 예측해 내는 대신에 bounding box의 priors를 조절합니다
그래도 여전히 x, y좌표를 즉각 찾아냅니다. 자세한 것은 논문을 참고해 주세요!
fully-convolutional model(Network) aka FCN
Fully connected Layer 대신에 1x1 convolution(합성곱층)을 사용하여 연산량을 줄인 모델이다.
CNN은 주로 출력층에 가면 이전층과 다음 층이 전부 full로 연결된 fully connected layer를 사용했는데, FCN이 나오고 나서 이 출력층을 1x1 convolution으로 대체하게 되면서 계산량과 시간을 매우 단축하게 되었다고 합니다.
hard negative
실제로는 거짓(negative)인데, 참(positive)이라고 예측하기 쉬운 데이터
YOLO v2에 대한 논문
YOLO9000: Better, Faster, Stronger
We introduce YOLO9000, a state-of-the-art, real-time object detection system that can detect over 9000 object categories. First we propose various improvements to the YOLO detection method, both novel and drawn from prior work. The improved model, YOLOv2,
arxiv.org
Version 3은 무엇이 달라졌는가?
YOLOv3는 몇가지 꼼수를 이용했습니다. 이것은 training을 효과적으로 할 수 있게 하고, perfomance를 증가시켜줍니다.
multi-scale prediction 뿐아니라, 더 나은 classifier backbone 등 을 사용했습니다.
이 또한 논문을 참고해주세요.
Pre-Trained Model(미리 학습된 모델)을 이용한 Detection 방법
이 부분은 이미 학습된 모델을 이용해서 YOLO detection을 해보는 내용입니다.
이미 학습된 모델은 weight파일로 darknet 사이트에서 배포됩니다.
(이 부분은 번역이 따로 필요 없이 그냥 따라해보면 되는 부분이기 때문에 생략합니다..)
Darknet은 "찾아낸 물체, 그것의 confidence(일치 정도), 찾아내는데 걸린 시간" 를 출력합니다.
우리는 opencv를 이용해서 컴파일을 진행하지 않기 때문에, 찾아낸 물체를 바로 보여줄 순 없습니다.
대신에 predictions.png에 저장됩니다. 해당 파일을 열기만 하면 찾아낸 물체들을 확인할 수 있습니다.

CPU를 사용해서 탐색한 경우 이미지 당 6~12초 정도 걸릴 수 있습니다. GPU를 사용한다면 더욱 더 빨리 실행이 가능합니다.
data라는 폴더에 여러가지 예시 이미지들이 있으니 테스트 해보세요.
테스트 방법
한장의 사진
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg./darknet detect cfg모델경로 weights모델경로 detection을 진행하고 싶은 사진 경로
이렇게 차례대로 입력해주면 됩니다.
여러장의 사진
detection을 진행하고 싶은 사진 경로를 빈칸으로 남겨두면 여러장의 사진을 한번에 테스트 해볼 수 있습니다!
./darknet detect cfg/yolov3.cfg yolov3.weights
또한, Ctrl+C를 이용해 종료가 가능합니다.
비슷한 내용인데 opencv를 이용해 테스트 해보는 방법이 있습니다. 아래를 참고해주세요
2021/03/07 - [졸업프로젝트/YOLO] - [YOLO]OpenCV를 이용한 YOLO
[YOLO]OpenCV를 이용한 YOLO
이미 학습된 모델을 테스트 해보는 방법입니다 1. openCV설치 iTerm에 작성 python3 -m pip install opencv-python 2. Jupyter notebook에서 테스트 해야하는데 나는 맥에또 Jupyter notebook이 없네 설치부터 하..
iagreebut.tistory.com
Detection의 임계치 변경하기
YOLO에서 객체를 찾아낼 때, 일치율의 임계치(threshold) 0.25로 설정되어 있습니다.
이 값은 다음과 같은 command를 이용해 변경이 가능합니다
-thresh <value>
다음과 같이 사용하면 됩니다
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0.5thresh를 50%이상으로 설정한 모습
Tiny YOLO ( YOLOv2 에서 나오는 내용)
Tiny YOLO는 *Darknet reference network를 기반으로 만들어 졌습니다. 매우 빠르지만 YOLO model보다는 부정확 합니다.
이 모델을 사용하기 위해서는 VOC로 학습시켜야 합니다.
완벽하지는 않지만 매우 빠릅니다. GPU를 이용하면 200FPS이상으로 작동합니다

Darknet Reference Model
이 모델은 작지만 매우 강력합니다.
이 모델은 1/10정도의 parameter를 이용하지만, AlexNet의 top-1과 top-5과 성능이 유사합니다.
출력층에 매우 큰 fully connected layer가 아닌 convolutional layer를 사용합니다.
AlexNet의 CPU보다 2배 정도 빠르며, vision application에 더 적합하다.

pjreddie.com/darknet/imagenet/#reference
ImageNet Classification
ImageNet Classification You can use Darknet to classify images for the 1000-class ImageNet challenge. If you haven't installed Darknet yet, you should do that first. Classifying With Pre-Trained Models Here are the commands to install Darknet, download a c
pjreddie.com
Tiny YOLOv3
우리는 매우 제약적인 환경(constrained enviroment)를 위해 매우 작은 모델을 만들었습니다. yolov3-tiny입니다.
VOC(Visual Object Classes)로 Training YOLO
YOLO를 맨 처음부터 학습시킬 수도 있습니다. 만약 다른 dataset, hyper-parameter, training regimes(제도, 요법)을 사용하고 싶다면 말이죠.
Pascal VOC dataset을 이용하여 어떻게 학습시키는지 알아봅시다
(여기서부터는 원문을 참고하시는게 좋을 것 같습니다 코드가 있으니..)
1. Pascal VOC Data 받아오기
YOLO를 학습시키기 위해서 2007~2012년에 해당하는 모든 VOC data가 필요합니다.
데이터는 이 사이트에서 다운 받을 수 있습니다.
이 모든 데이터를 다운 받을 디렉토리를 만들고 디렉토리 내에 다운받으세요
pjreddie.com/projects/pascal-voc-dataset-mirror/
Pascal VOC Dataset Mirror
Pascal VOC Dataset Mirror The Pascal VOC challenge is a very popular dataset for building and evaluating algorithms for image classification, object detection, and segmentation. However, the website goes down like all the time. In case you need the file, h
pjreddie.com
다운 받고 나면 모든 VOC 학습데이터가 들어있는 VOCdevkit/라는 서브디렉토리가 생길겁니다.
2. VOC를 위한 라벨 생성하기
이제 다크넷이 사용한 라벨 파일을 생성해야합니다. 다크넷은 각 이미지 마다 .txt파일을 필요로 합니다.
각 이미지마다 다음과 같이 이미지에 대한 내용을 기재합니다.
<object-class> <x> <y> <width> <height>
<x> <y> <width> <height>는 이미지의 넓이와 높이에 관한 내용을 적습니다.
이런 파일을 생성하기 위해 다크넷에서 제공하는 scripts/ 디렉토리 내의 voc_label.py 라는 것을 실행시킵니다.
//다운로드
wget https://pjreddie.com/media/files/voc_label.py
//실행
python voc_label.py
필요한 파일이 생성되었습니다.
VOCdevkit/VOC2007/labels/ 또는 VOCdevkit/VOC2012/labels/ 경로상에 라벨 파일이 여러개 생성될 것입니다.

가령 2007_test.txt 내부에는 2007년도의 이미지 파일 리스트와 이미지 set가 적혀 있을 것 입니다.
다크넷은 당신이 훈련시키고자 하는 모든 이미지에 대해 하나의 텍스트 파일을 요구합니다.
예를 들어, 2007년도의 테스트 데이터 셋(2007_test.txt )만 제외하고 나머지 모든 데이터를 학습시키고자 하면 다음과 같이 입력합니다.
이렇게 되면, 2007_test.txt를 제외하고 모든 나머지 파일들이 train.txt라는 하나의 큰 리스트로 합쳐진 모습을 볼 수 있습니다.
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
이제 필요한 모든 데이터가 준비되었습니다.
3. Pascal Data를 위한 cfg 수정하기
이제 다크넷 디렉토리로 이동하여, cfg/voc.data이라는 config file을 다음과 같이 수정합니다.
1 classes= 20
2 train = <path-to-voc>/train.txt
3 valid = <path-to-voc>2007_test.txt
4 names = data/voc.names
5 backup = backuppath-to-voc부분에는 위에서 만든 VOC data를 넣어둔 경로를 입력합니다.
4. 미리 학습된 convolutional weight(학습된 모델)을 다운받기
학습을 위해 ImageNet에서 이미 학습시켜둔 convolutional weight(model)을 사용할 것이므로 이를 다운받아 줍니다.
(파일 다운은 원본 사이트를 참조하세요 아니면 코드를 사용해서 다운받으셔도 됩니다)
wget https://pjreddie.com/media/files/darknet53.conv.74
5. 모델 학습시키기
이제 다음과 같은 명령어를 이용하여 모델을 학습시킵니다.
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
COCO를 이용하여 YOLO학습시키기
이번엔 VOC data가 아닌 COCO dataset을 이용하여 학습시켜봅시다.
1. COCO Data 다운받기
YOLO를 학습시키기 위해서 모든 COCO data와 label이 필요합니다.
여기서 사용할 scripts는 scirpts/get_coco_dataset.sh입니다. 데이터를 저장해 둘 디렉토리로 이동하여 저장합니다.
cp scripts/get_coco_dataset.sh data
cd data
bash get_coco_dataset.sh이제 Darknet에서 알아들을 수 있또록 라벨과 데이터를 생성해야합니다.
2. COCO를 위한 cfg 수정하기
이제 다크넷 디렉토리로 이동하여. cfg/coco.data config 파일을 올바르게 수정해야합니다.
1 classes= 80
2 train = <path-to-coco>/trainvalno5k.txt
3 valid = <path-to-coco>/5k.txt
4 names = data/coco.names
5 backup = backuppath-to-coco부분에는 위에서 만든 COCO data를 넣어둔 경로를 입력합니다.
또한, training을 위한 cfg모델로 수정해야 합니다.
cfg/yolo.cfg를 다음과 같이 수정합니다.
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=8
....
3. 모델 학습시키기
다음과 같은 명령어로 모델을 학습시킬 수 있습니다
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74여러개의 GPU를 사용할 수도 있습니다.
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74 -gpus 0,1,2,3checkpoint를 이용하여 stop & restart기능을 사용할 수도 있습니다
./darknet detector train cfg/coco.data cfg/yolov3.cfg backup/yolov3.backup -gpus 0,1,2,3
여기까지 DARKNET YOLOv3 공식 문서를 번역해보았습니다.
사실 들인 시간에 비해 엄청난 정보를 얻지는 못했다는 느낌이 들긴하는데.. 그래도 한번쯤 읽어봐야할 문서였으니 정리해두어서 좋네요.
제가 알고싶은건 cfg파일에 대한 내용들과 제가 만들어낸 데이터셋을 이용하여 학습시키는 방법이었는데
그에 대해서는 안나오고 VOC / COCO 라는 대표적으로 제공되는 데이터 셋을 이용해 학습시키는 방법이 나온 것 같습니다.
하지만, 이렇게 제공되는 대표적 데이터셋을 이용해 학습시키는 방법을 제대로 알아두면 분명 응용해서 할 수 있을 것입니다
yolo-voc.cfg와 yolo.cfg의 차이를 알게되어서 일단 마음이 놓이네요 ㅋㅋ 뭔가했어요 ㅎㅎ
다음엔 Darkflow의 공식문서(?)를 정독해보도록 하겠습니다
thtrieu/darkflow
Translate darknet to tensorflow. Load trained weights, retrain/fine-tune using tensorflow, export constant graph def to mobile devices - thtrieu/darkflow
github.com
'졸업프로젝트 > YOLO' 카테고리의 다른 글
| [YOLO] Image Labeling 의문 사항들 (0) | 2021.03.12 |
|---|---|
| [YOLO] python xml,이미지 파일 PNG to JPG (0) | 2021.03.10 |
| [YOLO]OpenCV를 이용한 YOLO (0) | 2021.03.07 |
| [YOLOdarkflow] Image Labeling (0) | 2021.02.24 |
| [Window10] YOLO Darkflow 설치하기 (1) | 2021.02.15 |


