Keras로 CNN 분류 모델 만들기!
멘땅에 헤딩! 완전 raw데이터를 가져다가 CNN 분류모델 학습까지 한번 해보도록 하자!
나는 이미 프로젝트를 끝냈고 .. 솔직히 말하면 정확도가 높은 모델 도출에 실패했다!
하지만 석/박사님들 말씀을 들어보니 정말 raw한 데이터이기 때문에 당연한 결과라고 하셨다
정말 거의 아무것도 모르는 상태로 매우 간단한 딥러닝책을 반권만 공부하고 프로젝트를 시작했다
pandas / numpy 등등을 하나도 모르고 python도 거의 까먹은 상태에다가 데이터를 만져보는것은 거의 처음이라 정말 막막했다
그래도 결국 어떻게든 결과물을 냈으니 한번 정리해보는 것도 나쁘지 않을 것 같아서 정리해본다
들어가기~
데이터를 분류하기 위해서는 일단 raw데이터를 받아와 전처리를 해야한다.
전처리는 필요한 정보만을 남기고 데이터를 깔끔하게 정리하거나, 적절한 단위로 데이터를 끊어 하나의 set으로 만든다거나, CNN이 받아들일 수 있는 형태로 데이터를 다듬어 주는 것을 뜻한다.
전처리를 올바르게 하기 위해서는 이 데이터가 어떻게 구성되어 있는지 알아야하며, <-raw data의 READ ME 파일을 읽어야함
전처리를 효과적으로 하기 위해서는 데이터에 대한 심도있는 분석이 필요하다 <- 이건 난이도가 높아서 깊게 하지 않았음
일단 이 프로젝트의 목적과 내가 사용할 데이터에 대해서 설명하기로 한다.
프로젝트의 목적
24가지의 일상 생활 동작에 대한 3축 가속도 센서(X,Y,Z) 데이터를 이용하여
데이터를 보고 해당 동작이 24가지중 무슨 동작인지 분류하는 CNN모델을 만드는 것이다.

데이터 설명
내가 사용할 데이터는
archive.ics.uci.edu/ml/datasets/PAMAP2+Physical+Activity+Monitoring
UCI Machine Learning Repository: PAMAP2 Physical Activity Monitoring Data Set
PAMAP2 Physical Activity Monitoring Data Set Download: Data Folder, Data Set Description Abstract: The PAMAP2 Physical Activity Monitoring dataset contains data of 18 different physical activities, performed by 9 subjects wearing 3 inertial measurement uni
archive.ics.uci.edu
이 사이트에서 다운받은 데이터를 사용했다

들어가보면 데이터에 대한 간략한 설명이 있는데, 실제와 다를 수도 있으니 데이터를 다운받아
READ ME 파일을 열심히 읽거나 실제 데이터를 확인하는 게 좋다
- 데이터 셋 특징 : Multivariate(종속 변수가 여러개 / 독립 변수의 수는 상관 없음) / Time-Series (시계열 데이터)
- Attribute 수 : 52개
- 관련된 Task : Classification(분류)
- 결측값 (Missing Values) : 있음
여기서 데이터를 다운받으면, pdf파일로 데이터에 대한 설명이 쓰여있고, 실제 데이터가 들어있는 dat파일이 있다.

여기서 폴더 2개를 제외한 다른 pdf파일의 내용은 다음과 같다
| 파일명 | 내용 |
| DataCollectionProtocol | Protocol파일에 있는 데이터가 어떤 순서로 진행되었는지에 대한 설명 |
| DescriptionOfActivities | 24가지(+0번)동작 중 18개 동작에 대한 부가설명 |
| PerformedActivitiesSummary | 9명의 피실험자가 0~24번까지의 동작을 얼마나 오래 했는지 통계 |
| ReadMe | 여러가지 정보들 |
| SubjectInformation |
실험에 참가한 9명 피실험자(Subject)의 신체 정보 |
전부 다 읽어보는 것이 좋지만 Readme가 가장 중요하다
Data Set Information (데이터 셋 정보)
다음 데이터는 9명의 피 실험자가 3가지의 IMU와 심박 수 측정기를 착용하고 18가지의 다른 신체활동을 한 결과를 측정한 데이터이다. 이 데이터 셋들은 데이터 활동 인식, 강도측정의 처리(processing)/ 세분화(segmentation)/특징 추출(feature extraction)과 분류(classification) 알고리즘을 발전시키거나 적용하는데 사용될 수 있다.
**센서**
Sampling frequency : 100Hz (어떤 현상이 1초에 100번 반복(진동)됨)
센서별 위치(3개의 IMU) -> 1IMU당 17개의 센서 정보가 들어가있다.
- 주로 사용하는 손의 손목(1IMU)
- 가슴(1IMU)
- 주로 사용하는 쪽의 발목(1IMU)
심장 박동수(Heart Rate)
Sampling frequency : ~9Hz (어떤 현상이 1초에 ??????~9번 반복(진동)됨)
**데이터 파일들**
Raw 센서데이터는 텍스트파일로 나누어져 있으며 형식은 .dat입니다.
1개의 데이터 파일당 한명의 실험자/타입(Protocol/Optional)으로 나누어져있습니다.
Missing Value는 NaN으로 표기되어 있습니다.
한 줄 당(row) 센서 데이터 instance 대한 time stamp와 label이 지정되어 있습니다.
데이터 파일은 54개의 column(각각의 row는 timestamp , activity label + 52개의 센서 데이터)를 가집니다

**Attribute 정보 **
54개의 Attribute는 다음과 같다
1. Timestamp
2. Activity ID(0~24까지)
3. 심박수(bpm)
4~20. IMU 손
21~37. IMU 가슴
38~54. IMU 발목
IMU당 17개의 Attribute(column) 목록
1. 온도
2~4. 3축 가속도 센서 (ms-2) scale : 16g, resolution : 13bit
5~17. 나머지 센서는 나는 사용하지 않음
0~24번까지의 활동 정보(activity id)

즉, 한 행은 100Hz단위로 기록되며(1초는 100행)
여기서 우리는 주로 사용하는 쪽 "손"의 3축 가속도 센서 X,Y,Z 와 그에 해당하는 활동정보 (label) 만을 사용하므로
54열중 4열만 사용하게 된다.

총 9명의 피실험자가 있으며, 데이터는 총 14개의 dat파일로 구성되어있고
하나의 dat파일에는 위와 같이 54열을 가진 한 행이 0.01초 단위로 기록되어 있다.

자세한 정보는 데이터를 받아서 파일을 읽어보시면 알 수 있습니다.
이제 이 데이터가 어떻게 구성되어 있는지는 알아보았습니다.
이제 이 데이터에서 필요한 데이터만을 남기고 제거한 후 -> 사용하는 쪽 "손"의 3축 가속도 센서 X,Y,Z 와 그에 해당하는 활동정보 (label) 만을 사용
데이터 스트림을 "각 activity id를 잘 구분할 수 있는 단위"로 나누면 참 좋다. -> 여기에 대해서 조금 알아보고 가자
지금까지 말한 내용을 대충 정리하면 이렇다

손에 센서를 부착하고 여러 동작을 하여 측정한다.
우리는 그것을 어떤 동작인지 정답에 해당하는 라벨을 붙여 모델에 제공하여 학습하게 한 후
정답을 빼고 데이터를 줬을때 어떤 동작인지 높은 정확도로 알아맞추는 모델을 만들어 내고 싶다
데이터를 어떤 단위로 나눌까?
어떤 단위라는 말이 맞는 말인지는 모르겠지만 무슨 뜻인지 설명하자면 이렇다
1개의 batch라고 생각하면된다.
학습시킬때 하나의 배치는 크기가 동일하다, 이 하나를 여러배치로 묶으면 미니배치가 되는 것인데
그렇다면 위와 같은 시계열 데이터를 같은 크기의 하나의 배치로 자르는 법은 특정(같은) 초 단위로 데이터를 나누는 것이다.
ex) 데이터를 30초 단위로 끊기(1초에 100행이므로 30초면 3000행) // (물론 다른 방법도 있을 수 있겠지만...)
이때 데이터를 몇 초 단위로 나눌 것인가? 는 아주 중요한 문제다
잘라진 데이터는 해당 행동의 특성을 잘 반영할 수 있어야 하기 때문이다
무슨 뜻이나면
walk(걷기)와 run(달리기) 데이터를 구분한다고 해보자

맨 처음 걷기 시작할때와 맨 처음 달리기를 막 시작할때의 속력은 비슷하기 때문에 두 동작을 맨 처음 3초만 봐서는 달리기인지 걷기인지 구분하기 어렵다.
그렇기 때문에 적절한 시간 단위로 잘라주어야 하는 것이다.
그 외에도 생길 수 있는 문제는 매우 다양하다
1) 누구는 매우 느리게 뛰고, 누구는 매우 빠르게 뛰면 측정값을 이용해 무엇이 걷기이고 무엇이 달리기인지 결론짓기가 애매하고 어렵다
2) 24가지 동작을 같은 단위로 잘랐을 때 동작마다 다른 특성을 가졌기 때문에 특정(해당) 단위가 모든 동작에 적절한 단위가 되기란 매우 어렵다.
걷는 동작과 달리는 동작은 예를들어 10초 단위로 끊었을때 구분이 가능하다고 한다면,
눕는 동작과 앉는 동작은 초반에 눕는 동작을 할때와 앉는 동작을 할때를 제외하고는 움직임이 없으므로
10초 단위로 끊었을때 움직임이 없는 부분은 동일해서 구분하기 어려울 수 있다.
그래서 모든 데이터가 적절하게 자신의 특성을 반영할 수 있는 단위를 발견하는 것이 매우 중요하다
기타 등등...
이게 바로 데이터에 대한 심도있는 이해가 필요한 이유이다.
데이터를 분석하여 적절한 단위로 짜르기 쉽게 도울 수 있는 하나의 방법은 데이터를 직접 그려보는 것이다
matplotlib을 사용하면 데이터를 그려볼 수 있다.
데이터를 그릴 때 주의할 점은 0~24의 데이터를 각각 데이터별로 모은 후 개별적으로 그려주어야 한다는 것이다
다음은 protocol폴더의 subject101.dat인 101번 피실험자가 실행한 동작들을 2분단위 그래프로 그려주는 코드이다
import matplotlib.pyplot as plt
#파일 불러오기 -> 파일경로만 다르게 바꾸면 한번에 처리가능
f = open("subject101.dat의 경로를 입력")
#Open subject101's data separated with space(공백) / 데이터 프레임으로
df = pd.read_table(f, sep="\s+",header=None)
#time stamp, activity_id, 3D-acceleration data (ms-2), scale: ±16g, resolution: 13-bit
#필요 없는 정보 제거
wanted_data = df[[1,4,5,6]]
#column이름 변경
wanted_data.columns = ['Activity_ID','X','Y','Z']
# activity num ( 1~24 ) : num 0번은 버리는 정보
activity_ids = range(1,25)
# activity num별로 1~24개의 dataframe(?) 생성 (file명 : file_activity_ids)
import sys
mod = sys.modules[__name__]
for i in activity_ids:
Activity_num = wanted_data['Activity_ID'] == i
setattr(mod, 'file_{}'.format(i),wanted_data[Activity_num])
#원하는 시간입력
time = 3000
for j in activity_ids:
#file_j 파일 불러와서 current file에 저장
current_file = getattr(mod,'file_{}'.format(j))
current_file = current_file[['X','Y','Z']]
current_file = current_file.reset_index(drop=True)
#draw data
fig,ax = plt.subplots(1,1)
ax.plot(current_file)
ax.set_xlim([0,4*time]) #0~12000행 즉, 2분의 데이터
#그래프 저장
dst = './'+str(j) + '.png'
plt.savefig(dst, dpi=300)
각각 행동에 대한 XYZ 데이터를 2분 단위로 시각화한 모습이다.
태그로 달린 동작을 보면 왜 XYZ데이터가 이런식인지 대충 감이온다
예를들어 누워있는 것은 움직임이 적은 정적인 그래프이고 walk와 run은 흔들리므로 변화가 큰데 run이 walk보다 변화가 더 크다

이 부분만 눈으로 놓고 봤을때는 2000~7000 / 7000~12000 정도 5000(50초 단위)로 패턴이 비슷하게 반복되는 것 같긴 하나
0~2000의 데이터는 버려져야 한다는 문제점
그리고 인간의 입장에서는 두 구간이 변화가 별로 없는 부분에서 동일하다고 느낄 수 있지만
컴퓨터 입장에서 파란선의 값을 보면
2000~7000구간은 6정도, 7000~12000구간은 0정도 이므로 둘이 같다고 인지하지 못할 수도 있다.
근데 누워있는데 왜저러지 뒤척거리나?

이것은 더 나누기 애매하다 앉았다가 일어났다를 반복한 것인지는 몰라도...
나눈다면 1000~4000 / 4000~7000 / 7000~10000 (30초단위)정도가 그나마 유사해보이는데
이마저도 lying때와 비슷한 문제점을 보인다

0~6000 / 6000~12000정도(60초)로 나눠볼 수 있겠지만 위와 유사하다

맨 앞부분과 5000대의 약간 부분만 제외하면 어디를 나누어도 괜찮을 것 같이 일정하고 유사한 모습을 보인다

walk와 비슷하나 조금더 격렬하게 움직이는 것을 볼 수 있다

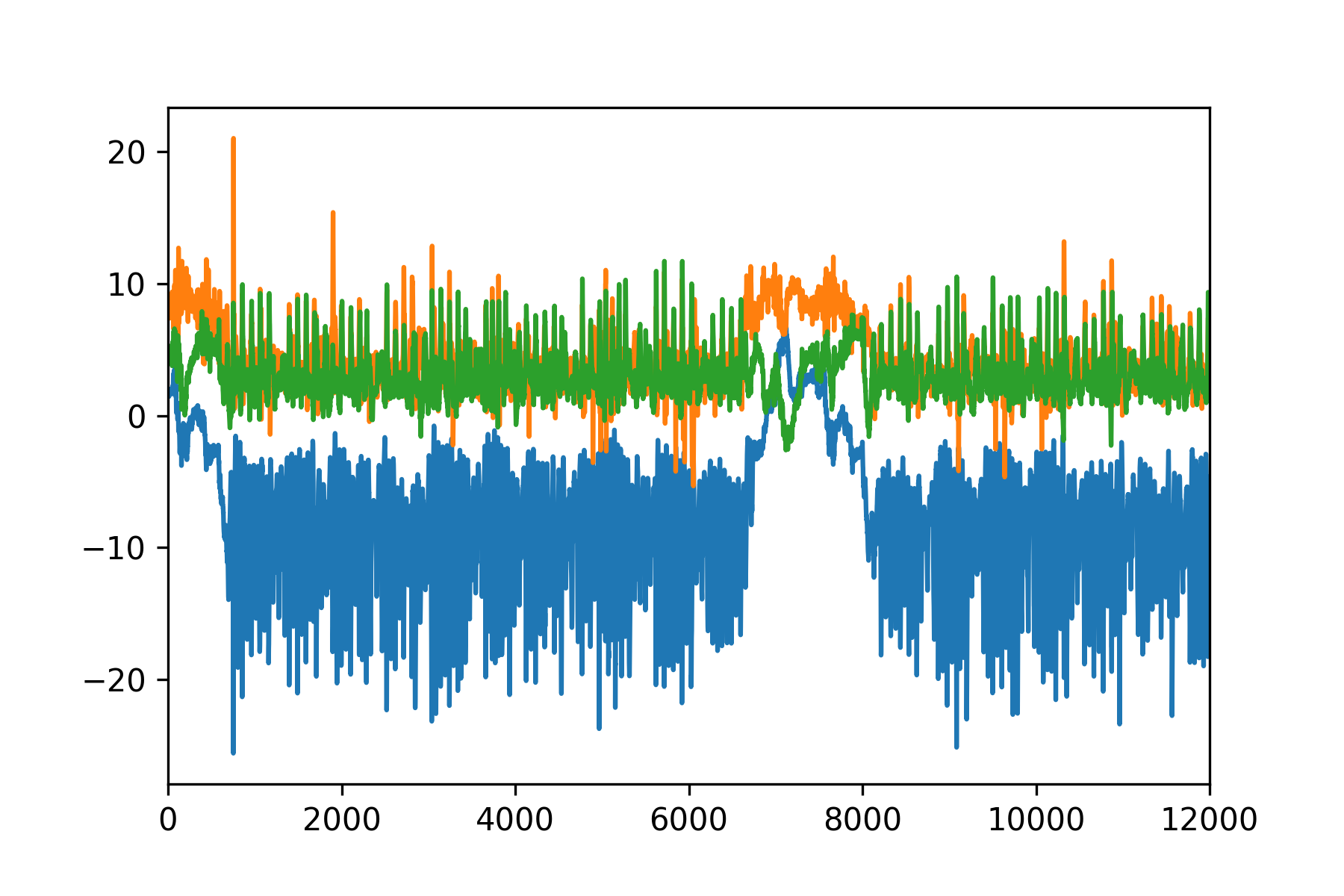
계단 오르내리기는 정말 유사하다 진심으로 인간이 봐도 모를 것 같다
하지만 데이터를 어느 단위로 나누냐는 측변에서는 1000의 배수 단위 정도면 무난하게 인식가능 할 것 같다

1000~3000까지 유사한 것을 보아 2000의 배수정도면 적절할 것 같다

지금 까지 종합한 결과 대충 60초 정도면 타협할 수 있을 것 같다
또한 모든 데이터에서 맨 처음 시작할 때 앞부분(뭔가 드릉드릉~함)을 잘라주면 더 정확한 결과를 얻을 수 있다는 느낌적인 느낌이 온다
데이터는 정확히 넣어줄수록 좋다
그러므로 데이터를 한번 그려보면서 개형을 파악하고, 각각 행동별 특성을 숙지하다보면
어떤식으로 전처리를 해야 더 정확하고 좋은 데이터를 얻을 수 있는지 감이 오기 때문에 아주 좋은 방법이다.
근데... 나는 30초 단위로 자를거다...
왜냐면 그렇게 해오라고 과제를 받았으니까...
(그리고 후에 가서 말하겠지만 데이터의 양도 너무적어서.. 너무 크게 자르면 데이터가 더적어진다..)
이 글은 내가 장렬히 CNN을 실패하고 조금 더 연구하고 후회하면서 쓴 글이기 때문에...
근데 컴퓨터 사양도 별로고 개강해서 다시 실험해볼 시간이 없다.. 쓰는걸로 만족하기로함
여러분은 모두 그려보시고 데이터를 충분히 파악한 후 하시면 더 좋을 것 같습니다.
~다음시간엔 RAW데이터에서 원하는 데이터만 가져와서 X/Y/Z를 따로따로 나눈 후 24가지로 나누어 라벨링하기를 해보도록 하겠습니다~
<참고>
[Python 시각화] 선 그래프 그리기 (matplotlib API)
참고글 : [Python] 피벗 (.pivot, .pivot_table) [Python 시각화] 막대 그래프 그리기 (matplotlib API) import pandas as pd import numpy as np from pandas import Series, DataFrame from numpy import nan as..
data-make.tistory.com
'ML > 프로젝트CNN' 카테고리의 다른 글
| [keras] CNN분류 모델 만들기 5 - 학습에 필요한 변인 (0) | 2020.08.20 |
|---|---|
| [keras] CNN분류 모델 만들기 4 - 기본 구조 잡기 (0) | 2020.08.20 |
| [keras] CNN분류 모델 만들기 3 - Training/Validation/Test set나누기 (0) | 2020.08.20 |
| [keras] CNN분류 모델 만들기 2 - 데이터 전처리 (4) | 2020.08.20 |
| [Colab]기본설정 + Tensorflow/Keras 버전 (0) | 2020.08.04 |



