졸업프로젝트 앱 (VIVA)에서는 사용자가 틀린 문제에 대한 자동 오답노트 생성 기능이 존재한다.
이를 위해서는 데이터베이스에 각 문제의 사진과 그에 대한 답안지의 이미지가 구축되어있어야 가능하다.
이를 위해서는 구할 수 있는 답지/문제지 pdf를 입력으로 주었을 때, 각 문제가 따로따로 이미지화하는 것이 요구된다.

즉, 다음과 같은 앱의 기능(오답노트) 에 들어갈 풀이와 문제 이미지를 생성해내야 한다.
1. 문제지 이미지 생성
목표) 문제집의 특정 페이지를 넣으면 문제만 크롭해서 저장하기
input : 수능완성 페이지 (png)

수능완성 (가)형 - 30page
output)
24~29번까지 문제 별개로 크롭된 이미지


이미지를 크롭하기 위해서는 이미지 단순화, 제거, 보정을 통해 형태를 파악해야하기 때문에
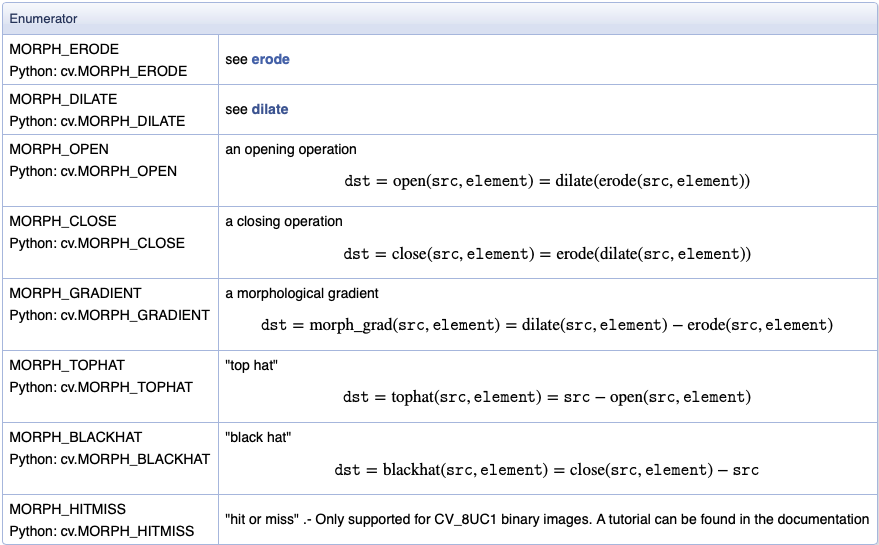
OpenCV에서 제공하는 Morphological Transformations 기능을 이용해야한다
아래글을 먼저 참고해서 숙지해야함
[OpenCV]Morphological Transformation
Morphological Transformations Theory Erosion : 제거 Dilation : 확장 Opening : Erosion → Dilation Closing : Dilation → Erosion Function cv2.erod() : Erosion cv2.dilate() : Dilation cv2.morphologyEx..
iagreebut.tistory.com
1. 전처리
이미지 흑백화 + 이진화 (이전글 참고
2021/01/11 - [졸업프로젝트/OpenCV] - [OpenCV] 이미지 이진화
def contour():
#원본 이미지
image = cv2.imread('/gdrive/MyDrive/cropStudy/suwan_ga/suwan_ga_030.png')
#흑백 이미지
imgray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) #원본 이미지와 흑백이미지가 따로 존재
#이미지 이진화
blur = cv2.GaussianBlur(imgray, ksize=(3,3), sigmaX=0)
thresh = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)[1]
cv2_imshow(thresh)
결과)

2. 이미지 외곽 추출
이진화 한 이미지에 대하여 외곽을 추출한다
Canny : edge를 찾아내는 알고리즘
cv2.Canny(image : edge를 찾아낼 이미지, threshold1 : min임계치, threshold2 : max임계치 )
Canny알고리즘은 모든 픽셀들의 edge를 검출한다.
검출하는 기준은 색이 급격하게 변하는 구간을 기준으로 한다.
색이 변하는 정도에 따라서 가지고있는 값이 있는데 해당 값이
min 임계치보다 작으면 edge가 아니고,
max 임계치보다 크면 edge이다.
min임계치와 max임계치 사이에 존재하는 경우 연결성에 초점을 두어 고려한다.

즉, 다음 그림의 경우 min과 max의 사이에 존재하는 것은 C,B이다.
B의 경우 전체 line이 min과 max사이에 존재하므로 edge가 아닌 것으로 판단한다.
하지만, C의 경우 line의 일부가 max임게치를 넘어선 범위에 존재하므로 edge라고 판단한다.
결국 min과 max임계치의 값이 모두 작을 수록 더 많은 edge를 검출해 낸다.
그렇기 때문에 threshold1,2의 값을 실험적으로 이미지에서 원하는 부분의 edge만 검출하도록 적절하게 찾아내야 한다.
min = 10 ~ max = 200
edge = cv2.Canny(imgray, 10, 200)
min값을 10으로 한 경우 원하지 않는 배경 로고 까지 edge로 판단된 것을 확인할 수 있다.
이 경우 min값의 크기를 높인다
min = 100 ~ max = 200
edge = cv2.Canny(imgray, 100, 200)

적절하게 원하는 문제부분들만 edge로 검출되었음을 확인할 수 있다
3.이미지 일반화
edge로 검출된 페이지에서 "번호와 문제와 보기"를 엮어서 하나의 범위로 지정해야한다.
서로 떨어진 edge들을 하나의 덩어리로 만들어야 하므로 Morphological Transformation중
- Closing : 전체적인 윤곽 파악에 적합
- Dilation(확장) : 경계가 부드러워지고, 구멍이 메워지는 효과
두 가지중 하나를 사용하는 것이 적합할 것이다
Closing
# Morph operations
edge = cv2.Canny(imgray, 100, 200)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(40,80))
closed = cv2.morphologyEx(edge, cv2.MORPH_CLOSE, kernel)
확인용으로 윤곽을 그려 확인해보면
# 확인용
contours, hierarchy = cv2.findContours(closed.copy(),cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours_image = cv2.drawContours(image, contours, -1, (0,255,0), 3)
cv2_imshow(contours_image)
findCountours
외곽을 찾는 함수
파라미터로 받는 이미지는 흑과 백으로만 이루어진 이미지(이진화된 이미지)여야 하며 0,1로만 구성되기 때문에
검은색배경에서 흰색 물체를 찾아내는 원리와 유사하다 -> Canny알고리즘으로 추출한 이미지 사용
cv2.findContours
cv2.findContours(image : 대상이되는 이미지url, mode : 관계를 정의하는 방법 , method : contours정보를 반환하는방법)contours(외곽을 저장한 배열)
hierarchy : contours들 간의 계층구조를 나타내는 배열
mode
둘의 관계를 어떤식으로 정의할 것인지 RETR_TREE : TREE관계로 배열을 리턴RETR_LIST : 계층관계를 고려하지 않음RETR_EXTERNAL : 가장 바깥쪽의 와곽만 추출해냄

method
contours정보를 꼭지점만을 저장할 것인지 모든 좌표를 반환할 것인지에 대한 내용을 결정

결과)

Dilation
# Morph operations
edge = cv2.Canny(imgray, 100, 200)
cv2_imshow(edge)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(40,80))
closed = cv2.morphologyEx(edge, cv2.MORPH_DILATE, kernel)
결과)

결과에서 확인할 수 있듯이 문제의 길이가 충분히 긴것들은 충분한 응집성이 생기지만
문제의 길이가 아주 짧은 것들 끼리는 응집성을 가지기 어렵다. ex) 04번문제
그렇다고 kernel의 크기를 키우면 오른쪽 부분에 있는 문제와 왼쪽 부분에 있는 문제가 하나의 문제로 인식된다

kernel=(150,80)
또한 중앙에 있는 선과 위쪽에 있는 선(단원명 부분)으로 인하여
문제끼리 적절한 연관성을 가지기 어렵다
즉, 중앙선과 단원명을 제거한 후에 시도하는 것이 좋아보인다.
하지만 중앙선과 단원명 부분을 검출해내 제거하는 것 보다는 윗단과 중앙선을 애초에 이미지에서 잘라 내는 것이 효율적이라고 생각된다
사용된 함수의 개념에 대한 설명)
Morphological Transformations
Theory
- Erosion : 제거
- Dilation : 확장
- Opening : Erosion → Dilation
- Closing : Dilation → Erosion
Function
- cv2.erod() : Erosion
- cv2.dilate() : Dilation
- cv2.morphologyEx() : Opening / Closing (매개변수를 이용하여 무엇을 선택할지 지정)
structing element
원하는 이미지를 스캔하여 특정 부분에 대하여 "Erosion/Dilation/Opening/Closing" 할 때 사용할 kernel(filter)을 만들어 줌
cv2.getStructuringElement(shape,ksize)
cv2.getStructuringElement(shape : Element의 모양, ksize : 커널의 크기 , anchor )
shape
사각형 : MORPH_RECT
십자가 : MORPH_CROSS
타원 모양 : MORPH_ELLIPSE
#사각형
ksize = (5,5)
[1,1,1,1,1],
[1,1,1,1,1],
[1,1,1,1,1],
[1,1,1,1,1],
[1,1,1,1,1]
#타원
ksize = (5,5)
[0,0,1,0,0],
[1,1,1,1,1],
[1,1,1,1,1],
[1,1,1,1,1],
[0,0,1,0,0]
#십자가
ksize = (5,5) / anchor= (2,3)
[0,1,0,0,0],
[0,1,0,0,0],
[1,1,1,1,1],
[0,1,0,0,0],
[0,1,0,0,0]
Erosion : 제거
원하는 이미지에 각 pixel에 structing element*를 스캔하면서 하나라도 0이 있는 경우 해당 pixel을 제거하는 방식
하나의 큰 이미지에서 작은 Object들을 제거하는 효과

Original Image에 대해 Struting Element를 적용하면 최종적으로 오른쪽의 결과를 얻게됨
erode()
cv2.erode(image : 적용을 원하는 이미지url, kernel : structing element, anchor : 해당 structing element내에서 제거를 원하는 픽셀, iteration : 제거를 반복할 횟수)
*anchor default : (-1,-1)Structing element를 Original image에 적용하여, 원본의 각 pixel 에 적용하여 겹치는 부분이 없는 부분이 하나라도 있으면
structing element 내의 anchor에 해당하는 픽셀을 제거함
Dilation : 확장
원하는 이미지에 각 pixel에 structing element*를 스캔하면서 하나라도 1이 있는 경우 해당 pixel을 채우는 하는 방식
경계가 부드러워지고, 구멍이 메워지는 효과

dilation()
cv2.dilation(image : 적용을 원하는 이미지url, kernel : structing element, anchor : 해당 structing element내에서 제거를 원하는 픽셀, iteration : 제거를 반복할 횟수)
*anchor default : (-1,-1)Structing element를 original image와 OR연산을 적용하여 (0,0인 경우만 0 이므로) 채워지는 효과를 얻음
Morphology : Opening(제거 후 확장) / Closing (확장 후 제거)
Erosion과 Dilation을 조합한 결과
- Opeing : Erosion적용 후 Dilation 적용. 작은 Object나 돌기 제거에 적합
- Closing : Dilation적용 후 Erosion 적용. 전체적인 윤곽 파악에 적합

morphologyEx()
cv2.morphologyEx(image : 적용을 원하는 이미지url, op : type of Morphological op(opening/closing), kernel : structing element, anchor : 해당 structing element내에서 제거를 원하는 픽셀, iteration : 제거를 반복할 횟수)
*anchor default : (-1,-1)
op
코드)
#OpenCV - 문제 크롭하기 (미완)
#라이브러리 임포트
import numpy as np
import cv2 #openCV package
from google.colab.patches import cv2_imshow
#구글 드라이브와 연동
from google.colab import drive
drive.mount('/gdrive')
#수능완성 page trim
#페이지에서 왼쪽,오른쪽 반페이지 분리
def imtrim(page):
x=300
w=1120
left = page[465:, x:x+w]
x=1480
right = page[465:,x:x+w]
return right,left
#반페이지를 입력받고 크롭하기
def contour(page_rl):
#이미지 흑백화
imgray = cv2.cvtColor(page_rl, cv2.COLOR_BGR2GRAY)
#이미지 이진화 (스캔본 처럼)
blur = cv2.GaussianBlur(imgray, ksize=(3,3), sigmaX=0)
thresh = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)[1]
# Morph operations
edge = cv2.Canny(imgray, 100, 200)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(1000,100))
closed = cv2.morphologyEx(edge, cv2.MORPH_CLOSE, kernel)
contours, hierarchy = cv2.findContours(closed.copy(),cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours_xy = np.array(contours)
contours_xy.shape
#한페이지 내의 모든 폐곡선 범위에 대해 실행
for c in contours:
#폐곡선 바운더리
x,y,w,h = cv2.boundingRect(c)
#바운더리를 이용해서 문제 크롭 후 보여주기
img_trim = page_rl[y:y+h , x:x+w]
cv2_imshow(img_trim)
#페이지 url을 입력하면
def problem_crop(image_url):
#이미지url을 open CV에 읽어들이기
imgfile = image_url
image = cv2.imread(imgfile)
#한 페이지를 반페이지로 나누기
right,left = imtrim(image)
#각 반페이지에 대해 크롭 진행
contour(right)
contour(left)
#함수실행
if __name__ == "__main__":
problem_crop('/gdrive/MyDrive/cropStudy/suwan_ga/suwan_ga_030.png')
위에서 말한 내용을 조합하여, 문제지 한페이지에 대한 이미지를 삽입했을 때, 문제부분만 잘려서 반환해주는 함수를 작성한다.
아이디어)

raw image
전체 이미지에서 윗단과 아랫단을 제거 한 후 (문제영역만 남김)

trimed image
페이지를 왼쪽부분과 오른쪽 부분으로 나눈 후

8page_left

8page_right
위의 내용과 유사하게 진행하면서 kernel사이즈의 x size를 충분히 키우면 검출해 낼 수 있을 것
1. 이미지 tirm : imtrim함수
#수능완성 page trim
def imtrim(page):
x=300
w=1120
left = page[465:3450, x:x+w]
x=1480
right = page[465:3450,x:x+w]
return right,left아랫단과 윗단을 제거한 후 페이지를 오른쪽 부분과 왼쪽 부분으로 나눔
그 후 right, left라는 변수에 저장한 후 return함
결과)

left

right
2. 이미지 전처리 + 외곽추출 + 일반화 : contour함수
#반페이지를 입력받고 크롭하기
def contour(page_rl):
#이미지 흑백화
imgray = cv2.cvtColor(page_rl, cv2.COLOR_BGR2GRAY)
#이미지 이진화 (스캔본 처럼)
blur = cv2.GaussianBlur(imgray, ksize=(3,3), sigmaX=0)
thresh = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)[1]
# Morph operations
edge = cv2.Canny(imgray, 100, 200)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(1000,100))
closed = cv2.morphologyEx(edge, cv2.MORPH_CLOSE, kernel)
contours, hierarchy = cv2.findContours(closed.copy(),cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)이제 하나의 페이지에 대해서는 RECT에서 가로x가 아무리 커져도 옆과 혼선될 일이 없으므로
가로부분을 최대한으로 크게 잡는 것이 오히려 모든 정보를 빼지 않고 담을 수 있으므로
ksize의 x 축을 크게 준다
결과 - left / right page각각 적용 )

left
-> 문제가 존재하지 않으므로 필요없는 페이지임

right
-> 문제가 존재하므로 필요한 페이지 이며, 3가지 문제가 각각 적절하게 묶였음을 알 수 있음
3. 한 페이지에 존재하는 각각의 문제를 따로 자르기 : contour함수
contours_xy = np.array(contours)
contours_xy.shape
#한페이지 내의 모든 폐곡선 범위에 대해 실행
for c in contours:
#폐곡선 바운더리
x,y,w,h = cv2.boundingRect(c)
#바운더리를 이용해서 문제 크롭 후 보여주기
img_trim = page_rl[y:y+h , x:x+w]
cv2_imshow(img_trim)for문을 이용해 각각의 contour에 대해 바운더리를 구한 후 그에 맞추어 잘라준다
저장하려면 imwrite를 사용해야 하지만 일단 미완이므로 imshow를 사용함
contours[] : 물체가 몇 개인지, 하나의 닫힌 선이 하나의 물체임
contours[][] : 각 좌표
contours [][][x][y] : x축과 y축
결과)
left page



right page

4번 이미지

5번 이미지

6번 이미지
원하는 대로 잘라진 것을 볼 수 있다
4. Refactoring : problem_crop함수
하나의 페이지를 입력하면
right/left로 trim한 후 각각에 대해 crop을 하는 함수로 최종 만들면
#페이지 url을 입력하면
def problem_crop(image_url):
#이미지url을 open CV에 읽어들이기
imgfile = image_url
image = cv2.imread(imgfile)
#한 페이지를 반페이지로 나누기
right,left = imtrim(image)
#각 반페이지에 대해 크롭 진행
contour(right)
contour(left)
image_url을 인풋으로 주면 각각에 대한 문제 크롭을 출력하는 함수가 최종으로 만들어 졌다
5. 해결해야 할 것
1) left page처럼 문제가 아닌 부분에 대해서는 저장할 필요가 없다
-> text를 인식하여 첫글자가 숫자가 아닌 이미지에 대해서는 저장하지 않음( tesseract 이용
2) 이미지 저장할 때 이름을 DB에 넣기 쉽게 저장
-> "문제집명_페이지_문제번호.png " 로 저장되게 만들기
전체코드)
#OpenCV - 문제 크롭하기 (미완)
#라이브러리 임포트
import numpy as np
import cv2 #openCV package
from google.colab.patches import cv2_imshow
#구글 드라이브와 연동
from google.colab import drive
drive.mount('/gdrive')
#수능완성 page trim
#페이지에서 왼쪽,오른쪽 반페이지 분리
def imtrim(page):
x=300
w=1120
left = page[465:, x:x+w]
x=1480
right = page[465:,x:x+w]
return right,left
#반페이지를 입력받고 크롭하기
def contour(page_rl):
#이미지 흑백화
imgray = cv2.cvtColor(page_rl, cv2.COLOR_BGR2GRAY)
#이미지 이진화 (스캔본 처럼)
blur = cv2.GaussianBlur(imgray, ksize=(3,3), sigmaX=0)
thresh = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)[1]
# Morph operations
edge = cv2.Canny(imgray, 100, 200)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(1000,100))
closed = cv2.morphologyEx(edge, cv2.MORPH_CLOSE, kernel)
contours, hierarchy = cv2.findContours(closed.copy(),cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours_xy = np.array(contours)
contours_xy.shape
#한페이지 내의 모든 폐곡선 범위에 대해 실행
for c in contours:
#폐곡선 바운더리
x,y,w,h = cv2.boundingRect(c)
#바운더리를 이용해서 문제 크롭 후 보여주기
img_trim = page_rl[y:y+h , x:x+w]
cv2_imshow(img_trim)
#페이지 url을 입력하면
def problem_crop(image_url):
#이미지url을 open CV에 읽어들이기
imgfile = image_url
image = cv2.imread(imgfile)
#한 페이지를 반페이지로 나누기
right,left = imtrim(image)
#각 반페이지에 대해 크롭 진행
contour(right)
contour(left)
#함수실행
if __name__ == "__main__":
problem_crop('/gdrive/MyDrive/cropStudy/suwan_ga/suwan_ga_030.png')
실행결과
input
수능특강 (가)형 _ 8pgae

output)
6개의 이미지

left_1

left_2

left_3

right_1

right_2

right_3
다음과 같이 문제집 이미지를 한 페이지 입력으로 받아서, 문제만 나누어 진 모습을 볼 수 있다.
2. 답안지 이미지 생성
답안지도 문제지와 유사한 방법이 사용되지만, 답안지는 한페이지 내에 존재하지 않고 나누어져 있는 경우가 있기 때문에,
나누어진 번호를 하나로 합치는 방법이 추가적으로 요구된다.
또한, 간격이 좁아 위의 방법을 사용하기 어려워 다른 방법을 사용하였다.
목표) 문제집 답지의 특정 페이지를 넣으면 각 문제별로 크롭하여 저장하기
input : 수능완성 답안지(png)

수능완성2021 (가)형 답지 - 2page

수능완성 2021 (가)형 답지 - 3page
output)
(10번이전 일부 문제 포함) 10번 ~21번(약간 잘림) 까지의 이미지

10번

20번
아이디어)
1. 전체 페이지에서 윗단과아랫단 제거 -> 문제영역만 남기기 (trim이용)
2. 페이지를 왼쪽 부분과 오른쪽 부분으로 나눔 -> 중앙 라인 제거
* issue 1) 왼쪽과 오른쪽 부분의 가로 크기는 같아야 할 것
issue 2) 홀수 페이지와 짝수 페이지의 중앙 선 부분의 위치가 다름
3. "답" 이미지를 중심으로 일정 여백을 더하여 해당 부분을 자르면, 모든 문제에 대해서 잘라낼 수 있음

"답"이미지
* issue) 페이지의 맨 하단에 있는 "답"이미지가 없는 부분(문제의 시작부분 끝부분은 다음페이지에 있는 경우)은 잘라지지 않음 해결 필요 -> 예 ) 2페이지 12,15번 / 3페이지 18번, 21번
4. 답이 다음 페이지에 이어지는 경우 다음 컷과 이어주기
->예시 : 위 2,3페이지 사이에 걸쳐있는 15번과 같은 경우 2페이지에 존재하는 15번 부분과 다음페이지에 있는 "답"이미지 이전까지잘린 두 이미지를 합치기
* issue) 이를 위해서는 읽는 순서가 (흡사 DFS TREE)
- 페이지 순서대로 ( 2p -> 3p )
- 페이지의 왼쪽의 윗쪽부터 아래쪽까지 ( 10번->11번->12번 (1) -> 12번(1) )
- 페이지의 오른쪽 윗쪽에서 아랫쪽까지 ( -> 12번(2) -> 13번 -> 14번 -> .... )
다음과 같아야만 다음컷과 이을 때 정확한 순서가 맞추어진다 12번(1)->12번(2)
Image trim
- 전체 페이지에서 윗단과아랫단 제거 -> 문제영역만 남기기 (trim이용)
- 페이지를 왼쪽 부분과 오른쪽 부분으로 나눔 -> 중앙 라인 제거
def imtrim(page,page_num):
#페이지 번호 string에서 int형으로 변환
page_num = int(page_num)
#짝수 페이지
if (page_num%2 == 0):
left = page[150:-130, 100:855]
right = page[150:-130,880:-137]
#홀수 페이지
else:
left = page[150:-130, 145:900]
right = page[150:-130,905:-112]
# 왼쪽페이지 먼저 리턴(순서대로)
return left,right짝수 페이지와 홀수 페이지의 경우 가운데 선 부분의 위치가 다르므로 다르게 잘라주어야 한다.
그래서 main에서 페이지 부분만 따로 추출하여 매개변수로 넘겨준 후, int형으로 변경하여 사용하였다.
잘린 페이지 범위는 실험적인 값으로 정한 것 , 가로는 775으로 맞추었음
"답"이미지를 기준으로 밑부분으로 잘라내기
ORDER
- 이미지 흑백화
- 템플릿 매칭
- 매칭 기준으로 자르기
전체 내용
def contour(page_rl):
#이미지 흑백화
imgray = cv2.cvtColor(page_rl, cv2.COLOR_BGR2GRAY)
#추출하려는 이미지
template = cv2.imread('/gdrive/MyDrive/ProjectStudy/answer_temp.png',0)
w, h = template.shape[::-1]
#템플릿 매칭
res = cv2.matchTemplate(imgray,template,cv2.TM_CCOEFF_NORMED)
threshold = 0.5
loc = np.where( res >= threshold)
#for문 내에서 사용할 변수 초기화
y_now = 0 #현재 자를 이미지의 y좌표
pt_now = 0 #현재 탐지한 "답"이미지의 y좌표
#탐지한 "답"이미지의 갯수만큼 반복
for pt in zip(*loc[::-1]):
#탐지한 "답"이미지의 y좌표
pt_past = pt_now # 이전값
pt_now = pt[1] #현재값
# 자를 y축 좌표 계산 (y_past : 시작좌표 / y_now : 끝좌표
y_past = y_now # 이전에 자른 부분(이전 단계의 끝좌표)으로 시작을 대치
y_now = pt_now + h + 25 #( "답"이미지의 left,top의 y좌표 + 이미지 height + 여백 )
#같은 "답"이미지가 여러번 탐지되는 부분을 자르는 것을 방지
if (pt_now >= pt_past+3):
img_trim = page_rl[y_past:y_now,:] # 원본 이미지를 계산한 좌표로 자르기
include(img_trim,qnum) # 잘린 이미지를 저장
# 맨 마지막 부분을 위해 1회 더 수행
img_trim = page_rl[y_now:,:]
include(img_trim,qnum)
이미지 흑백화 및 템플릿 매칭
#이미지 흑백화
imgray = cv2.cvtColor(page_rl, cv2.COLOR_BGR2GRAY)
#추출하려는 "답"이미지
template = cv2.imread('/gdrive/MyDrive/ProjectStudy/answer_temp.png',0)
w, h = template.shape[::-1]
#템플릿 매칭
res = cv2.matchTemplate(imgray,template,cv2.TM_CCOEFF_NORMED)
threshold = 0.5
#매칭되는 이미지의 좌표(loc = {array[y1, y2,...] and array[x1,x2,...]})
loc = np.where( res >= threshold)2021/01/18 - [졸업프로젝트/OpenCV] - [OpenCV] 이미지에서 특정 이미지 찾아내기
[OpenCV] 이미지에서 특정 이미지 찾아내기
답지에서 해당 답의 영역만을 추출하기 위해서는 다음과 같은 "답"이라는 이미지를 답지 페이지내에서 찾아낸 후 해당 이미지를 기준으로 그 아래를 자르면 된다 그래서 일단 이번 게시글에서
iagreebut.tistory.com
해당 게시글 참조!
매칭 기준으로 자르기
#for문 내에서 사용할 변수 초기화
y_now = 0 #현재 자를 이미지의 y좌표
pt_now = 0 #현재 탐지한 "답"이미지의 y좌표
#탐지한 "답"이미지의 갯수만큼 반복
for pt in zip(*loc[::-1]):
#
pt_past = pt_now
pt_now = pt[1]
# 자를 y축 좌표 계산 (y_past : 시작좌표 / y_now : 끝좌표
y_past = y_now # 이전에 자른 부분(이전 단계의 끝좌표)으로 시작을 대치
y_now = pt_now + h + 25 #( "답"이미지의 left,top의 y좌표 + 이미지 height + 여백 )
#같은 "답"이미지가 여러번 탐지되는 부분을 자르는 것을 방지
if (pt_now >= pt_past+3):
img_trim = page_rl[y_past:y_now,:] # 원본 이미지를 계산한 좌표로 자르기
include(img_trim,qnum) # 잘린 이미지를 저장
# 맨 마지막 부분을 위해 1회 더 수행
img_trim = page_rl[y_now:,:]
include(img_trim,qnum)여기는 삽질을 좀 오래했기 때문에 따로 글을 씀
2021/01/20 - [졸업프로젝트/OpenCV] - [OpenCV] 답지 문제별로 자르기(2) - 오류
해당 이미지 (page_rl) 한 페이지의 오른쪽 또는 왼쪽 부분 중 하나 내에서
모든 "답"이미지를 찾아낸다
이는 loc상에 저장되고 zip( *loc[::-1] )을 이용하여 해당 "답"이미지의 (x,y)좌표 로 저장되며
하나하나 pt[0] : x좌표 / pt[1] : y좌표 에 크기 순서대로 저장된다. ( 즉, 윗쪽에 존재하는 것 부터)
y_past에는 이전에 잘렸던 부분을 저장하고, y_now에는 새로운 "답"이미지의 y좌표를 저장하여
y_past부분 ~ y_now부분까지 잘라주면 된다
2페이지의 왼쪽 페이지 부분을 예시로 설명하면 다음과 같다

저장하기
#저장할이미지 , 해당 이미지의 고유번호(+1씩증가)
def include(cropped,qnum):
#전역변수 qnum을 전역변수로서 사용하기 위해
global qnum
#파일명 = 저장경로 + 고유번호 + _pa 페이지수 . png
newfile=save_path+str(qnum)+"_pg"+j+".png"
#해당 경로에 파일을 저장
cv2.imwrite(newfile,cropped)
#저장을 완료했기 때문에 고유번호 1증가
qnum=qnum+1각각 크롭된 문제마다 고유번호를 부여하기로 했다(문제와 답지의 고유번호가 같음 -> db검색시 용이)
고유번호인 qnum은 저장될때 마다 1씩증가하게 하며,
전역변수를 main에 선언해두고 사용한다 (밑에나옴)
크롭함수로 모으기
#페이지 url을 입력하면
def problem_crop(image_url,page_num):
#이미지url을 open CV에 읽어들이기
imgfile = image_url
image = cv2.imread(imgfile)
#image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#한 페이지를 반페이지로 나누기
left,right = imtrim(image,page_num)
#각 반페이지에 대해 크롭 진행
contour(left)
contour(right)지금까지 작성한 imtrim / contour함수를 사용해서 이미지 url과 page 넘버를 입력하면,
원하는 경로에 자동으로 크롭된 번호를 저장해주는 함수를 작성한다
imtrim을 반환하는 순서를 left , right
contour를 진행하는 순서를 left -> right
로 해주어야 왼쪽 페이지부터 결과를 받을 수 있다
메인함수
#함수실행
if __name__ == "__main__":
#고유번호 (전역변수로 사용할 것)
qnum=1
#이미지를 불러올 경로, 저장경로
load_path='/gdrive/MyDrive/ProjectStudy/answers/raw_data/Suwan_ga/2021/example/'
save_path='/gdrive/MyDrive/ProjectStudy/yj/ans_test2/'
os.chdir(load_path)
#해당 경로에서 .png로 끝나는 모든 이미지를 배열로 저장
images=glob.glob('./*.png')
#폴더내 이미지 순서대로 불러오기
images.sort()
#이미지의 수 만큼 반복
for i in range(len(images)):
#하나의 이미지 경로를 저장
filename=images[i]
#파일 이름에서 페이지 이름을 추출
page_num=filename[20:23]
j=page_num
#이미지 경로와 파일경로를 이용해서 크롭
problem_crop(filename,j)
images.sort를 이용하여 페이지를 순서대로 받아오게한다 (2page->3page)
전체코드)
! apt install tesseract-ocr
! apt install libtesseract-dev
! pip install Pillow
! pip install pytesseract
! sudo apt-get install tesseract-ocr-script-hang tesseract-ocr-script-hang-vert
#라이브러리 임포트
import numpy as np
import cv2 #openCV package
from google.colab.patches import cv2_imshow
import re
import pytesseract
import glob
import os
import time
from PIL import ImageEnhance, ImageFilter, Image
from matplotlib import pyplot as plt
#구글 드라이브와 연동
from google.colab import drive
drive.mount('/gdrive')
#수능완성 page trim
def imtrim(page,page_num):
page_num = int(page_num)
#짝수
if (page_num%2 == 0):
left = page[150:-130, 100:855]
right = page[150:-130,880:-137]
#홀수
else:
left = page[150:-130, 145:900]
right = page[150:-130,905:-112]
return left,right
#반페이지를 입력받고 크롭하기
def contour(page_rl):
imgray = cv2.cvtColor(page_rl, cv2.COLOR_BGR2GRAY)
#추출하려는 이미지
template = cv2.imread('/gdrive/MyDrive/ProjectStudy/answer_temp.png',0)
w, h = template.shape[::-1]
res = cv2.matchTemplate(imgray,template,cv2.TM_CCOEFF_NORMED)
threshold = 0.5
loc = np.where( res >= threshold)
y_now = 0
pt_now = 0
for pt in zip(*loc[::-1]):
pt_past = pt_now
pt_now = pt[1]
y_past = y_now
y_now = pt_now + h + 25
if (pt_now >= pt_past+3): #a lot of +1 kind of same pts
img_trim = page_rl[y_past:y_now,:]
cv2_imshow(img_trim)
#include(img_trim,qnum)
img_trim = page_rl[y_now:,:]
#include(img_trim,qnum)
cv2_imshow(img_trim)
def include(cropped,num):
global qnum
newfile=save_path+str(num)+"_pg"+j+".png"
#print(newfile)
#print(num)
cv2_imshow(cropped)
#print("===============================================")
cv2.imwrite(newfile,cropped)
qnum=qnum+1
#페이지 url을 입력하면 크롭
def problem_crop(image_url,page_num):
#이미지url을 open CV에 읽어들이기
imgfile = image_url
image = cv2.imread(imgfile)
#image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#한 페이지를 반페이지로 나누기
left,right = imtrim(image,page_num)
#각 반페이지에 대해 크롭 진행
contour(left)
contour(right)
#함수실행
if __name__ == "__main__":
qnum=1
load_path='/gdrive/MyDrive/ProjectStudy/answers/raw_data/Suwan_ga/2021/example/'
save_path='/gdrive/MyDrive/ProjectStudy/yj/ans_test2/'
os.chdir(load_path)
images=glob.glob('./*.png')
#폴더내 이미지 순서대로 불러오기
images.sort()
print(images)
for i in range(len(images)):
filename=images[i]
page_num=filename[20:23]
j=page_num
problem_crop(filename,j)
결과)
input 상단에 2~3페이지
output

2페이지 맨 첫번째 9번(2) / 파일명 : 1_pg002.png

2페이지 두번째 10번 / 파일명 : 2_pg002.png
(중략)

2페이지 마지막 15번(1) / 파일명 : 8_pg002.png

3페이지 맨 처음 15번(2) / 파일명 : 9_pg003.png
(중략)

3페이지 마지막 전 / 16_pg003.png

3페이지 마지막 / 파일명 : 17_pg003.png
페이지가 분리되어 쪼개진 하나의 답을 하나의 이미지로 합치기

2page 왼쪽 페이지 8번
(중략)

2p 오른쪽 페이지 15번(1)

3p 왼쪽 페이지 15번(2)
위의 사진 2개와 같은 사진을 하나로 합쳐야한다
아이디어)
이미지를 차례대로 받아오면서,
"답"이미지가 존재하는 경우 이미지를 그냥 저장
"답"이미지가 존재하지 않는 경우 배열에 이미지를 저장해두고,
그 이후로 최초의 "답"이미지를 보유한 사진이 나오면
배열에 저장해둔 사진을 차례대로 꺼내 이어서 저장해준다
이를 위해 flag를 이용한다.
"답"이미지를 찾아서 이미지를 저장한 경우는 flag = 1
"답"이미지가 없는 이미지를 만나 배열에 저장하는 경우는 flag = 0
사용할 변수 초기화
qnum=1
flag = 1
noans_count=0
image_arr = [None]*8qnum : 저장할 이미지에 부여할 고유번호
flag : 위쪽 참고
noans_count : 이미지 경로를 저장해둘 배열의 index로 사용할 변수 , 0으로 초기화
imag_arr : 이미지 경로를 저장할 배열
파이썬에서 리스트의 크기를 설정하고 초기화하는 방법은 다음과 같다
list = [None] * (list의 길이)
이미지 내에 "답"이미지가 있는지 확인하기
#이미지 합치기
def combine_image(image_url):
global flag
global image_arr
global noans_count
image = cv2.imread(image_url)
imgray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
template = cv2.imread('/gdrive/MyDrive/ProjectStudy/answer_temp.png',0)
res = cv2.matchTemplate(imgray, template, cv2.TM_CCOEFF_NORMED)
threshold = .55
loc = np.where(res >= threshold)
length = len(loc[0])
먼저 이전 게시글에서 한 방법과 동일하게 matchTemplate를 이용하여
해당 이미지 내에 "답"이미지가 있는지 검사한다
이미지 내에 "답"이미지가 있는지 검사하는 방법은 loc[0]또는 loc[1]의 길이를 출력해보는 것이다.
* len(loc)는 array[(x좌표의 배열)], array[(y좌표의 배열)] <- x좌표/y좌표 라서 무조건 다 2임
중요한건 어레이가 비어있는지 이라서
loc[0] / loc[1] 이렇게 해야 비어있는건지 아닌지 알 수 있음
"답"이라는 이미지가 없는 경우
#"답"이미지가 없는 이미지의 경우
if (length <= 0):
#이미지의 경로를 image_arr배열에 저장
image_arr[noans_count] = image_url
#배열 index를 증가시킴
noans_count=noans_count+1
#flag를 0으로 설정
flag = 0
image_arr이라는 배열의 현재 index(noans_count)에 이미지의 경로를 저장한다
(그냥 이미지를 저장하는 방법에서 오류가 났기 때문에 string인 경로를 저장하는 방법을 사용했다)
저장했으면,
(매우 긴 해설의 경우 여러 이미지를 합쳐야 할 수 있으므로) index를 하나 증가시킨다.
그런 뒤 flag를 0으로 설정한다
이미지 합치기
flag가 0이어서 배열에 이미지 경로가 1개 이상 저장되어 있는데,
"답"이미지를 가진 이미지( 이어 붙일 이미지의 마지막 부분)가 입력된 경우
#배열에 이미지 경로가 저장되어 있고(flag = 0 ) "답"이미지를 가진 이미지를 찾은 경우
elif (length >0 and flag ==0):
#여태까지 배열에 저장된 모든 이미지를 이어줌
for i in range(noans_count-1,-1,-1):
image_noans = cv2.imread(image_arr[i])
image = cv2.vconcat([image_noans,image])
noans_count = noans_count-1
#이어서 하나로 만든 이미지를 저장
include(image,qnum)
#배열 index를 0으로 초기화
if (noans_count < 0):
noans_count = 0
#flag를 1으로 설정
flag = 1
배열에 저장해둔 이미지 경로로 cv2.imread를 이용해 이미지를 읽어온다.
for i in range(noans_count-1, -1, -1)
range(시작 수 , 끝수 -1 , 간격)
noans_count - 1 부터 0까지 1씩 감소( -1씩 증가 )
noans_count는 image_arr의 마지막 index인데, 채울 때 마다 +1을 했기 때문에
아직 채워지지 않은 칸에 있기 때문에 -1을 해주어야한다.
0부터 채웠기 때문에 0까지 해주어야 하며, 1씩 감소시켜서 사용해야한다.
vconcat([위쪽 이미지, 아래쪽 이미지])
cv2.vconcat([image_noans,image])이미지를 세로 방향으로 합쳐주는 함수로, 앞쪽에 쓴 이미지가 위쪽으로 뒤쪽에 쓴 이미지가 아래쪽으로 간다.
index가 줄어들 수록 위쪽에 존재해야 하는 이미지 이므로 image_noans에 저장해 둔 이미지를 앞쪽에 써주어야 한다.
for문을 index 0까지 돈 경우
배열에 저장되었던 이미지가 전부 사용되었으므로
index를 초기화해주고, 합친 이미지를 저장해준다.
이미지를 저장했으므로 flag를 1로 변경해준다.
이미 온전한 이미지
#이미지가 온전한 (문제번호~"답"이미지까지 존재하는) 이미지인 경우
else:
#이미지를 저장
include(image,qnum)
flag=1
이미 처음부터 온전한 이미지의 경우 그냥 저장해 준 뒤
flag를 1로 설정해준다.
함수 전체
#이미지 합치기
def combine_image(image_url):
global flag
global image_arr
global noans_count
image = cv2.imread(image_url)
imgray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
template = cv2.imread('/gdrive/MyDrive/ProjectStudy/answer_temp.png',0)
res = cv2.matchTemplate(imgray, template, cv2.TM_CCOEFF_NORMED)
threshold = .55
loc = np.where(res >= threshold)
length = len(loc[0])
#"답"이미지가 없는 이미지의 경우
if (length <= 0):
#이미지의 경로를 image_arr배열에 저장
image_arr[noans_count] = image_url
#배열 index를 증가시킴
noans_count=noans_count+1
#flag를 0으로 설정
flag = 0
#배열에 이미지 경로가 저장되어 있고(flag = 0 ) "답"이미지를 가진 이미지를 찾은 경우
elif (length >0 and flag ==0):
#여태까지 배열에 저장된 모든 이미지를 이어줌
for i in range(noans_count-1,-1,-1):
image_noans = cv2.imread(image_arr[i])
image = cv2.vconcat([image_noans,image])
noans_count = noans_count-1
#이어서 하나로 만든 이미지를 저장
include(image,qnum)
#배열 index를 0으로 초기화
if (noans_count < 0):
noans_count = 0
#flag를 1으로 설정
flag = 1
#이미지가 온전한 (문제번호~"답"이미지까지 존재하는) 이미지인 경우
else:
#이미지를 저장
include(image,qnum)
flag=1
특정 경로에서 이미지를 순서대로 불러와서(sort()함수 사용)
combine_image함수에 적용시키면 다음과 같은 결과를 얻을 수 있다
결과)

15번이 합쳐진 모습
(나머지는 생략)
물론 이 방법으로 할 경우
이미 잘라진 이미지에 빠진이미지나 중복이미지 등 이상한 이미지가 있으면안된다
전체코드)
! apt install tesseract-ocr
! apt install libtesseract-dev
! pip install Pillow
! pip install pytesseract
! sudo apt-get install tesseract-ocr-script-hang tesseract-ocr-script-hang-vert
#라이브러리 임포트
import numpy as np
import cv2 #openCV package
from google.colab.patches import cv2_imshow
import re
import pytesseract
import glob
import os
import time
from PIL import ImageEnhance, ImageFilter, Image
from matplotlib import pyplot as plt
#구글 드라이브와 연동
from google.colab import drive
drive.mount('/gdrive')
#이미지 저장 함수
def include(cropped,num):
global qnum
number = str(num)
#식별번호를 4자리로 맞추기 위해
if (len(number)==1):
number = '000'+str(num)
elif (len(number)==2):
number = '00'+str(num)
else:
number = '0'+str(num)
#파일이름
newfile=save_path+str(num)+"_pg"+j+".png"
print(newfile)
#파일저장
cv2.imwrite(newfile,cropped)
#고유번호 1 증가
qnum=qnum+1
#경로 자동 생성 함수
def make_path_SW():
book_list=['2021','2020','2019','2018','2017']
for i in range(len(book_list)):
path=book_list[i]+'/'
path_list.append(path)
#이미지 합치기
def combine_image(image_url):
global flag
global image_arr
global noans_count
image = cv2.imread(image_url)
imgray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
template = cv2.imread('/gdrive/MyDrive/ProjectStudy/answer_temp.png',0)
res = cv2.matchTemplate(imgray, template, cv2.TM_CCOEFF_NORMED)
threshold = .55
loc = np.where(res >= threshold)
length = len(loc[0])
#"답"이미지가 없는 이미지의 경우
if (length <= 0):
#이미지의 경로를 image_arr배열에 저장
image_arr[noans_count] = image_url
#배열 index를 증가시킴
noans_count=noans_count+1
#flag를 0으로 설정
flag = 0
#배열에 이미지 경로가 저장되어 있고(flag = 0 ) "답"이미지를 가진 이미지를 찾은 경우
elif (length >0 and flag ==0):
#여태까지 배열에 저장된 모든 이미지를 이어줌
for i in range(noans_count-1,-1,-1):
image_noans = cv2.imread(image_arr[i])
image = cv2.vconcat([image_noans,image])
noans_count = noans_count-1
#이어서 하나로 만든 이미지를 저장
include(image,qnum)
#배열 index를 0으로 초기화
if (noans_count < 0):
noans_count = 0
#flag를 1으로 설정
flag = 1
#이미지가 온전한 (문제번호~"답"이미지까지 존재하는) 이미지인 경우
else:
#이미지를 저장
include(image,qnum)
flag=1
#함수실행
if __name__ == "__main__":
path_list=[]
make_path_SW()
path_prev='/gdrive/MyDrive/ProjectStudy/answers/'
path_back='/Suwan_na/'
for i in range(len(path_list)):
qnum=1
flag = 1
noans_count=0
image_arr = [None]*8
load_path=path_prev+'revised_cropped'+path_back+path_list[i]
save_path=path_prev+'cropped_final'+path_back+path_list[i]
os.chdir(load_path)
images=glob.glob('./*.png')
#폴더내 이미지 순서대로 불러오기
images.sort()
#print(images)
for i in range(len(images)):
filename=images[i]
page_num=filename[-7:-4]
page_url = load_path+images[i]
j=page_num
combine_image(page_url)
다음과 같은 방법으로 보유한 전체 문제지와 답안지(수능완성 2017-2021 / 2017-2021 년도 평가원, 교육청 모의고사)
에 대한 이미지 데이터를 생성했다.