[keras] CNN분류 모델 만들기 2 - 데이터 전처리
지난 시간에 데이터를 분석하고 데이터에 대해서 알아보았는데
이번에는 그때 알아낸 것을 토대로 데이터를 적절한 단위로 나누어 보도록 한다.
근데 난.. 딱히 적절하지는 않은 30초를 골랐다 그 이유는 전에 말했듯 그게과제여서
1. 데이터를 30초 단위로 나누고 라벨링하기
데이터 30초 단위로 나누고 라벨링하기

54열의 raw 데이터를 필요한 열인 2열,5,6,7열을 남기고 자른다.
각각 XYZ별로 acitivity 24가지를 분리해서 각각 행동당 30초 단위로 자른 후 라벨링한다
라벨링이란 사용자가 원하는 정보를 붙여서 정리하는건데
activity id는 필수이며, 그 외로 subject number, time stamp 그외 추가 기록할만한 사항들을 기록하면된다.
이렇게 14개의 파일이 따로따로 존재하기 때문에 subject num label은 가능해졌지만
14개의 파일을 또 따로따로 처리해서 합쳐주어야한다.
** 물론 python 파일 입출력으로 파일을 한번에 불러들인 후 한 행 당 3000열이 차면(1초 100열(100Hz)이므로 3000열)
라벨링 후 줄바꿈하여 하는 방법도 있다
이것이 더 보편적이고 좋은 방법이긴 한데 용량제한에 걸릴 수도 있다.

나는 다음의 코드를 각 파일당 한번 씩 수행하여 14번 실행한 후 X / Y / Z를 따로 따로 파일에 저장해 합쳐주었다.
import numpy as np
import pandas as pd
import os
from pandas import Series, DataFrame필요한 것 import
파일 불러오기
#파일 불러오기 -> 파일경로만 다르게 바꾸면 한번에 처리가능
f = open("/subject101.dat") # 101~109까지와 optional 도 한번씩 해서 14개를 다르게 처리
#파일이름 저장(subject??.dat) = 피실험자 번호 -> 라벨링을 위해
f_name = os.path.basename(f.name)
#Open subject101's data separated with space(공백) / 데이터 프레임으로
df = pd.read_table(f, sep="\s+",header=None)파일을 불러온 후,
나의 파일은 공백을 기준으로 데이터가 나누어져 있으므로 공백으로 나누어서 데이터프레임으로 만듭니다.
header = None을 하지 않으면 맨 첫 행이 column name으로 지정됩니다.
df를 출력해보면 다음과 같습니다(subject101.dat file의 내용)

라벨링을 위한 데이터 준비
subject number
#파일 이름 (실험자 번호, dat)으로 나누기
f_name = f_name.split('.')
#실험자 이름만 남기기 ,labeling시 사용
f_name = f_name[0]
#확인용
f_namesubject no을 라벨링시 사용하기 위해서
파일명을 이용해 subject no을 저장해둡니다.

activity_name
#Activity ids ,활동 번호 / 데이터프레임으로 ㅈㅔ작
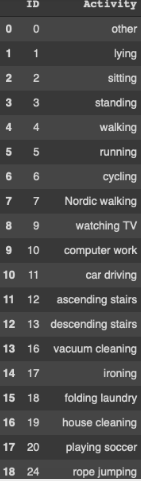
activity_list = {"ID" : [0,1,2,3,4,5,6,7,9,10,11,12,13,16,17,18,19,20,24],
"Activity" : ["other","lying","sitting","standing","walking","running","cycling","Nordic walking","watching TV","computer work","car driving","ascending stairs","descending stairs","vacuum cleaning","ironing","folding laundry","house cleaning","playing soccer","rope jumping"]}
act_ids=pd.DataFrame(activity_list)라벨링을 위해서 activity_id와 activity_name을 데이터프레임으로 만들어줍니다.
activity_id를 이용해서 activity_name을 라벨링 하기 위함입니다.
-> 데이터 프레임으로 만들기에는 너무 간단하고 변동이 없을 표라서 dictionary?인가 다른걸로 만들면 좋다고 하는데 이거까지 수정할 시간은 없어서..
필요한 정보만 남기고 제거
#time stamp, activity_id, 3D-acceleration data (ms-2), scale: ±16g, resolution: 13-bit
#필요 없는 정보 제거
wanted_data = df[[0,1,4,5,6]]
#column이름 변경
wanted_data.columns = ['TimeStamp','Activity_ID','X','Y','Z']
54열의 다양한 데이터
심장박동 / 가슴에 달은 센서의 데이터 등등은 필요없기 때문에 뺴고
dataframe df에서 time stamp / activity _ id / 3축 가속도 센서 X Y Z 부분 ,
총 5개의 열만 남겨 wanted_data라는 새로운 데이터프레임을 만들어 주었습니다.

activity_id에 따라 별도의 파일로 나누기
# activity num ( 1~24 ) : num 0번은 버리는 정보
activity_ids = range(1,25)
# activity num별로 1~24개의 dataframe(?) 생성 (file명 : file_activity_ids)
import sys
mod = sys.modules[__name__]
for i in activity_ids:
Activity_num = wanted_data['Activity_ID'] == i
setattr(mod, 'file_{}'.format(i),wanted_data[Activity_num])0은 버리는 정보이므로 ( 동작과 동작 사이의 버려지는 부분의 데이터임 )
범위를 1~24로 하여 "Activity_id"열이 i와 같을때의 데이터를 모아 file_(activity_id)라는 데이터프레임에 각각 넣어줍니다.
출력해보면 다음과 같습니다.


** for문을 이용하여 서로 다른 이름의 데이터 만들기 **
import sys
mod = sys.modules[__name__]
for i in 원하는 범위:
setattr(mod, '파일이름_{숫자가 들어갈 부분}'.format(i), 해당 파일(?)에 넣을 데이터)이렇게 해주시면
파일이름_1 , 파일이름_2 ...
이라는 이름으로 새로운 파일이 생성되고 맨 뒤에 매개변수로 넣어준 데이터가 해당 이름을 가진 파일에 각각 들어가게됩니다.
파일이라고 하기는 좀 그렇고 데이터프레임? 은 아닌것 같은데.. 정확하게 무엇인지는 안찾아봐서
데이터프레임 처럼 이용가능하긴 한 것 같습니다.
이를 이제 for문으로 꺼내서? 사용할 때는 다음과 같이 해주시면됩니다.
for j in 범위:
#파일이름_j 파일 불러와서 current file에 저장
current_file = getattr(mod,'파일이름_{}'.format(j))
X Y Z 데이터 만들기
이제 file_(activity_id)에 저장해 둔 데이터를 한번씩 불러와 30초 단위로 끊은 후
해당 행에 라벨을 activity_id ( for문의 j와 같을 것 ) , activity_name , subject , number 로 넣어봅시다
#X축을 30초씩 끊어서 저장할 dataframe생성
data_X = pd.DataFrame()
#file_activity_ids를 file_1~file_24까지
for j in activity_ids:
#file_j 파일 불러와서 current file에 저장
current_file = getattr(mod,'file_{}'.format(j))
#file의 길이가 0이면 해당 동작을 수행하지 않았으므로 제외
if current_file.index.size!=0:
#시작 인덱스 = 0, 끝 인덱스 = 길이 -1
start = 0
end = current_file.index.size-1
i = start
while i < end:
#30초 단위로 잘라 thirty_sec에 저장
#100Hz이므로 30초면 3000개
s = i
f = s+3000
#3000개 행(30초), X열(2열) 추출
thirty_sec = current_file.iloc[s:f,2]
#index 번호 초기화
thirty_sec=thirty_sec.reset_index(drop=True)
#행을 열로 변경해서 3000행-> 3000열을 가진 1개의 행으로 변경
thirty_sec=thirty_sec.T
#라벨링 label
#추가정보 1 : activity_id
thirty_sec['activity_id'] = j
#추가정보 2 : 해당 activity_id가 무슨 동작인지 미리 만들어둔 표에서 가져옴
need = act_ids.loc[act_ids["ID"]==j]
thirty_sec['activity_name'] = need.iloc[0,1]
#피실험자
thirty_sec['subject_no'] = f_name
#108번이 왼손잡이길래 넣어봄
#if f_name == "subject108":
# thirty_sec['extra_info'] = "left_handed"
#thirty_sec을 빈 데이터 프레임 data_X에 저장
#저장할 dataframe에 행 추가
data_X = data_X.append(thirty_sec, ignore_index=True)
#끝index를 시작 index로
i = f
#새로운 시작 index가 file_j의 맨 마지막 index보다 커지면 종료
if end<i:
break위의 코드를 Y열의 경우 3 , Z열의 경우 4로 설정하면
XYZ를 따로따로 만들어 낼 수 있습니다. (-> Y/Z 을 만드는 법 코드는 생략)
출력해보면 다음과 같습니다.

XYZ파일 csv파일로 저장하기
#파일명
file_out_X='/'+f_name+'_protocol_X.csv'
file_out_Y='/'+f_name+'_protocol_Y.csv'
file_out_Z='/'+f_name+'_protocol_Z.csv'
#subject101의 X축 데이터 csv로 저장
data_X.to_csv(file_out_X,header=False, index=False)
#subject101의 Y축 데이터 csv로 저장
data_Y.to_csv(file_out_Y,header=False, index=False)
#subject101의 Z축 데이터 csv로 저장
data_Z.to_csv(file_out_Z,header=False, index=False)
csv합치기
실험자별로 각각 protocol version 9개 / optional version 6개로 따로따로 만들어진 csv파일을
1개의 파일로 합쳐봅시다
terminal을 열어준 뒤
해당 파일이 존재하는 곳으로 cd를 이용해 이동한 후
cat *.csv > dataset_X.csv해주면 해당 폴더에 들어있는 모든 csv파일이 dataset_X.csv라는 이름을 가진 하나의 csv파일로 합쳐집니다.

csv파일을 엑셀로 열어보면 다음과 같습니다.
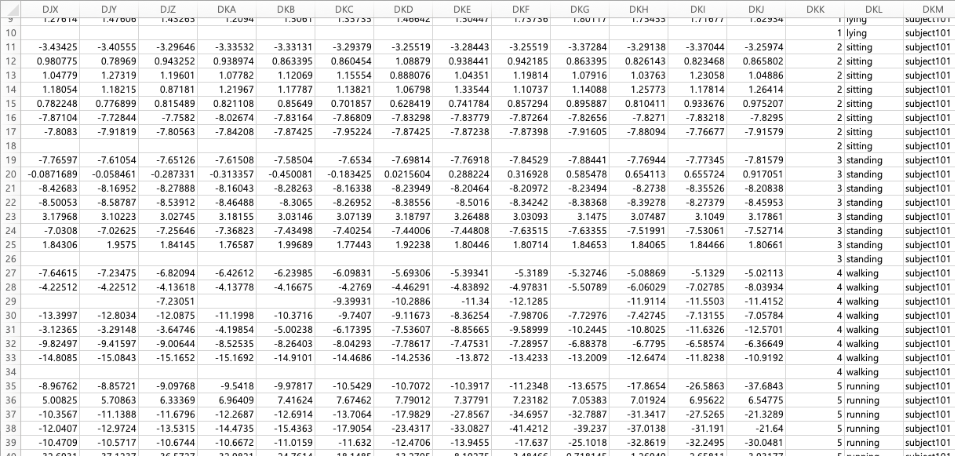
결과적으로 저는 "960행 3000열(+3 label 열) 의 X / Y / Z 데이터를 얻게되었습니다
완성
2. 결측값 처리
이대로 사용할 수도 있지만 한가지 문제가 더있습니다
바로 "결측값"인데, dataframe상에서 NaN으로 처리된 부분과 엑셀상에서 봤을때 빈칸인 부분입니다.
한마디로 데이터가 측정되지 않아 빈칸으로 남겨진 것인데,
데이터마다 다르겠지만 나의 데이터에는 크게 두가지 종류의 결측값이 있다.
<정말 측정되지 않은 부분>

이렇게 중간중간에 몇개씩 존재할 수도 있고, (뭐 센서의 오류나 등등으로 인해 중간에 값이 비어버린 것)
<30초로 자르고 남은부분>

이렇게 거의 한줄에 대부분 결측값이 존재하는 것도 있다
예를들어 달리기를 총 4분 10초했는데 30초간 잘랐으니 마지막 3000열은 10초인 1000열만 차있고 2000열은 빈칸으로 남아버린 경우이다.
결측값을 처리하는 방법에는 여러가지가 있다.
아예 삭제해버리는 방법 / 한가지 값으로 채워주는 방법(최소/ 최대 / 임의로 지정한 하나의 수 등등) / 주변값을 조사하여 평균치 등등을 채워넣어주는 방법
결측값을 처리하는 것은 아주 중요하다. 그냥 데이터만 봐도 알겠지만 저렇게 결측값이 많은데 어떻게 제대로 된 학습을 할 수 있겠는가..?
그런데 여기서는 자세히 다루지 않을 것이고 구글링 해보면 엄청나게 많이 나온다.
여러분은 더 좋은 방법을 사용해 보세요~ 찾아보면 많이 나와요 저는 이렇게 하는게 일단 과제였음.
여기서는 어떤 방법을 사용할 거냐면

여기서 주의해야할 점은 XYZ 세개를 통틀어 최솟값을 더 해주어야 한다는 것이다.
그리고 이 그림을 보면 감이 왔을 것 같은데 저렇게 틈새에 있는 결측값을 평균이나 적절한 값으로 채워진다는게 무슨 뜻인지 대충 감이 왔을 거다
아마 수치해석 쪽 ? 통계쪽 지식이 필요한데 난 그런게 없다.. 산술기하평균...? 분명 수치해석 들었는데 기억이 안나서 연구하면서 공부함..
일단 여기서는 이런 방법을 써서 결측값을 메운다.
import
import numpy as np
import pandas as pd
import os
from pandas import Series, DataFrame필요 없는 것 같기도 하다
데이터 불러오기
#파일 불러오기
dataset_X= pd.read_csv("dataset_X.csv", header=None)
dataset_Y= pd.read_csv("dataset_Y.csv", header=None)
dataset_Z= pd.read_csv("dataset_Z.csv", header=None)XYZ 를 전부 불러와서 데이터프레임으로 만들어 준다.
최솟값 구하기
각 열에서의 최솟값
dataframe.min() 함수를 사용하면 각 열에서의 최솟값을 찾을 수 있다.
이를 이용할 것
#각 열에서 최솟값만을 구해서구해 Series로 구성
min_set_X = pd.Series(dataset_X.min())
min_set_Y = pd.Series(dataset_Y.min())
min_set_Z = pd.Series(dataset_Z.min())
3000 , 3001 , 3002 열은 데이터가 아닌 라벨이므로 제외 시켜준다.
#3000열 부터는 extra정보 이므로 제외
find_min_X = min_set_X.iloc[0:3000]
find_min_Y = min_set_Y.iloc[0:3000]
find_min_Z = min_set_Z.iloc[0:3000]
이제 각각의 최솟값을 한번더 구해준다.
#3000행 1열 이므로 여기서의 최소값 == 데이터 전체의 최소
min_X = find_min_X.min()
min_Y = find_min_Y.min()
min_Z = find_min_Z.min()그러면 min_X / min_Y / min_Z 는 각각의 최소값이 된다.
우리는 이 셋중에 제일 작은 값을 사용할 것이고, 가장 작은 값은 (내기준) min_X였으므로
최솟값 더해주기
이제 모든 데이터에 라벨을 제외한 부분에 min_X만큼을 더해준다.
#원본 데이터의 0~2999열에 최솟값의 절댓값을 더 해줌
dataset_X.iloc[:,0:3000] = dataset_X.iloc[:,0:3000] + abs(min_X)
dataset_Y.iloc[:,0:3000] = dataset_Y.iloc[:,0:3000] + abs(min_X)
dataset_Z.iloc[:,0:3000] = dataset_Z.iloc[:,0:3000] + abs(min_X)
위의 최솟값 구하기를 다시실행해 보았을때 최솟값이 0이면 성공
결측값을 -1로 채우기
#결측값 -1로 채우기
dataset_X = dataset_X.fillna(-1)
dataset_Y = dataset_Y.fillna(-1)
dataset_Z = dataset_Z.fillna(-1)를 하면 결측값이 -1로 채워진다
저장하기
#dataset_?_m.csv로 저장
dataset_X.to_csv("/dataset_X_15sec_m.csv",header=False, index=False)
dataset_Y.to_csv("/dataset_Y_15sec_m.csv",header=False, index=False)
dataset_Z.to_csv("/dataset_Z_15sec_m.csv",header=False, index=False)
이제 결측값이 처리되었다.
3. 데이터 형태 전처리
데이터를 모델에 넣어주려면 X,Y,Z의 30초단위로 나눈 각각 데이터를 한세트로 넣어주어야 합니다.
즉 다음 그림과 같은 3개의 데이터를 한줄씩 짝지어 1개의 batch로 만들어 넣어주어야 합니다.
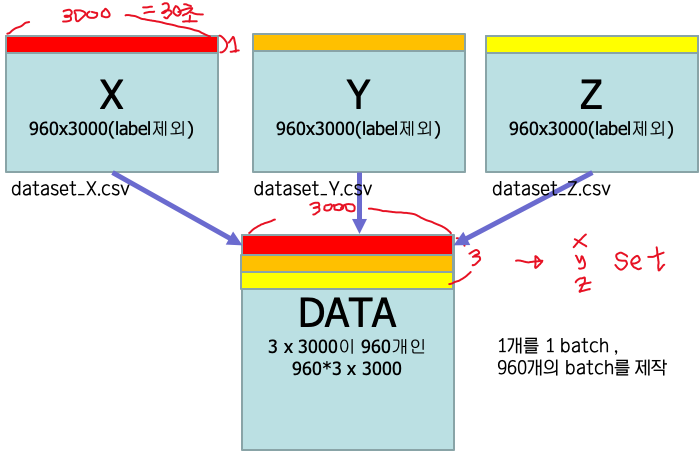
이를 한번에 저렇게 만드는 것보다 중간단계로 아래와 같은 모양으로 만들어주게 되면, 훨씬 편하게 넣어줄 수 있습니다.

이번 글에서는 이를 한줄로 만드는 것 까지 해보도록 하겠습니다.
** 여기서 당연히 X/Y/Z데이터는 raw데이터에 같은 행에 있던 친구들끼리 짝지어주는게 맞습니다.
저희는 이미 모든 데이터를 동일하게 30초단위로 나누었으므로 x,y,z 데이터가 각각 이미 raw에서 동일한 행이었던것은 같은 위치에 존재하므로 이대로 진행하면 되겠습니다. (물론 당연히 동일하니 라벨도 동일합니다)
데이터 불러오기
#데이터 불러오기
dataset_X = pd.read_csv("X",header=None)
dataset_Y = pd.read_csv("Y",header=None)
dataset_Z = pd.read_csv("Z",header=None)
데이터 셋 다듬기
#dataframe의 길이만큼 반복하기 위해 필요한 변수
length = dataset_X.index.stop
#X,Y에서 label을 제거
dataset_X = dataset_X.iloc[:,0:3000]
dataset_Y = dataset_Y.iloc[:,0:3000]
dataset_Z = dataset_Z.iloc[:,0:3003] #마지막 z는 label이 포함됨라벨은 X,Y,Z모두에게 (같은내용으로) 되어있는데
한줄로 합치려고하면 맨 마지막 부분인 Z부분만 라벨이 있으면 되기 때문에 X,Y부분의 라벨은 제거해줍니다.
한줄씩 한 행으로 합치기
#X,Y,Z,label 을 한줄로 ㄷㅔ이터 합치기
xyz_data = pd.DataFrame()
for i in range(0,length):
x = dataset_X.iloc[i,:]
y = dataset_Y.iloc[i,:]
z = dataset_Z.iloc[i,:]
h = pd.concat([x,y],ignore_index=True)
h = pd.concat([h,z],ignore_index=True)
xyz_data = xyz_data.append(h,ignore_index=True)
for문을 이용해서 x,y,z의 길이(동일함) 반복해서
한줄씩 뽑아와 이를 concat으로 한줄로 합쳐
xyz_data라는 데이터 프레임에 한행씩 넣어줍니다.
저장하기
#합쳐진 데이터 저장
xyz_data.to_csv("/xyz_data_9000.csv",header=False, index=False)
결과적으로 이러한 데이터가 960행(줄) 생겼습니다
저희에게는 총 960개의 데이터가 있고 이 데이터의 종류는 24개인거네요 (엄청적다!)